3-2/기계학습
2주차-Dataset, 특징공간
Donghun Kang
2024. 9. 17. 18:28
- 연립방정식과 시스템

- 기계학습과 시스템

- 기계학습
학습: Dataset(input, target)을 가지고 model의 parameters를 찾는 것.
EX) Linear regression

기계학습의 모델링(Modeling)
- 어떤 모델을 쓸 것인가? / 입력의 형태를 보고 설계한다.
- Dataset의 특징에 따라 설계가 달라진다.

- 데이터의 Type
- Numerical data => Regression (내일의 최고 온도 예측/ 나이에 따른 독서량)
EX) 나이, 신장(키), 꽃받침 길이
- Internal data: IQ, 연도, 온도
- Ratio data: 개수, 길이, 무게 => "0"을 정의할 수 있다.(곱셈, 나눗셈 가능)
- Categorical data => Classification (내일 강수 여부 예측/ 이미지의 동물 분류)
EX) 성별, 결혼 여부, 학력
- Norminal data: 색상, 동물의 종류
- Oridinal data: 고객 만족도, 별 평점 => "순서"를 정할 수 있다.
- 특정 공간 안에서 거리 측정
차원에 무관하게 수식 적용 가능

- 기계학습에 적용되는 데이터
- 데이터 생성 과정을 정확히 알 수 없음 (환율, 날씨)
- 주어진 훈련 집합으로 예측 모델 또는 생성 모델을 근사 추정 (예측에 영향을 주는 모든 데이터를 수집할 수 없다.)
- 데이터베이스의 중요성
- 데이터베이스의 품질: 다양한 데이터를 충분한 양만큼 수집 => 추정 정확도 높아짐
Q) 왜소한 데이터베이스로 어떻게 높은 성능을 달성할까?
A) 방대한 공간에서 실제 데이터가 발생하는 곳은 매우 작은 부분.
특정 공간의 아주 작은 공간만을 사용함.
일정한 규칙에 따라 매끄럽게 변화하는 공간으로 표현할 수 있다면 좋은 성능을 낸다.
- Underfitting
모델의 "용량이 작아" 오차가 클 수 밖에 없는 현상

- Overfitting
- 훈련집합에 대해 거의 완벽하게 근사.
- "새로운" 데이터를 예측한다면 큰 문제 발생 => "용량이 크기 때문"

- 기계학습의 목표
낮은 바이어스와 낮은 분산을 가진 예측기 제작이 목표
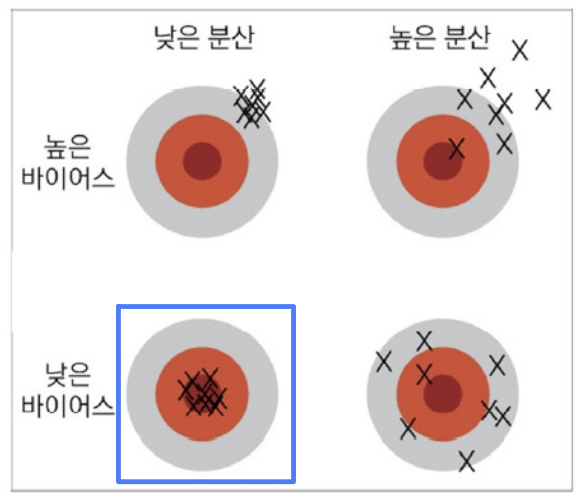
바이어스와 분산은 트레이드오프 관계
일반적으로
- "용량이 작은 모델" => 바이어스 크고 분산이 적음.
- "복잡한 모델" => 바이어스 작고 분산은 큼.

데이터를 더 많이 수집하면 일반화 능력이 향상

데이터 수집에는 많은 비용이 듦.
=> 데이터 증대(Augumentation)
- 훈련집합에 있는 샘플을 변형/ 회전 또는 와핑