3-1/Deep Learning
9주차-ML Strategy
Donghun Kang
2024. 5. 11. 16:13
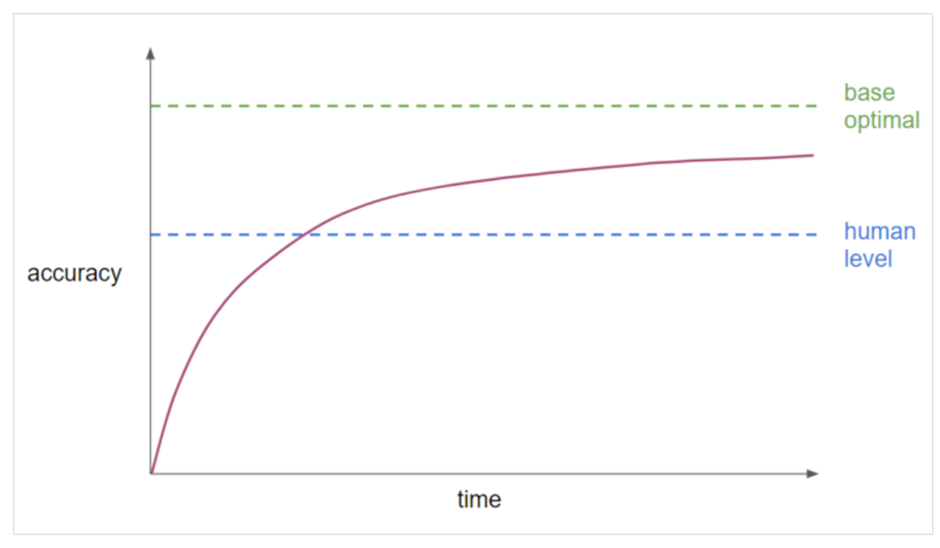
- Bayes optimal error
모델의 이론상 가능한 최저의 오차값. overfitting이 되지 않는 이상 이 값을 뛰어 넘을 수 없다.
이론적으로 가능한 최고의 정확도 값
알고리즘의 성능(보라색 선)은 시간이 흐르더라도 bayes optimal error에는 도달할 수 없다.
Q) human level performance에 인접하면 성능이 떨어지는 이유는?
A) 1. human level perfermance와 bayes optimal error의 차이가 크게 안나는 경우
2. human level perfermance가 나오지 않을때 사용하는 성능향상 기법을 쓸 수 없기 때문

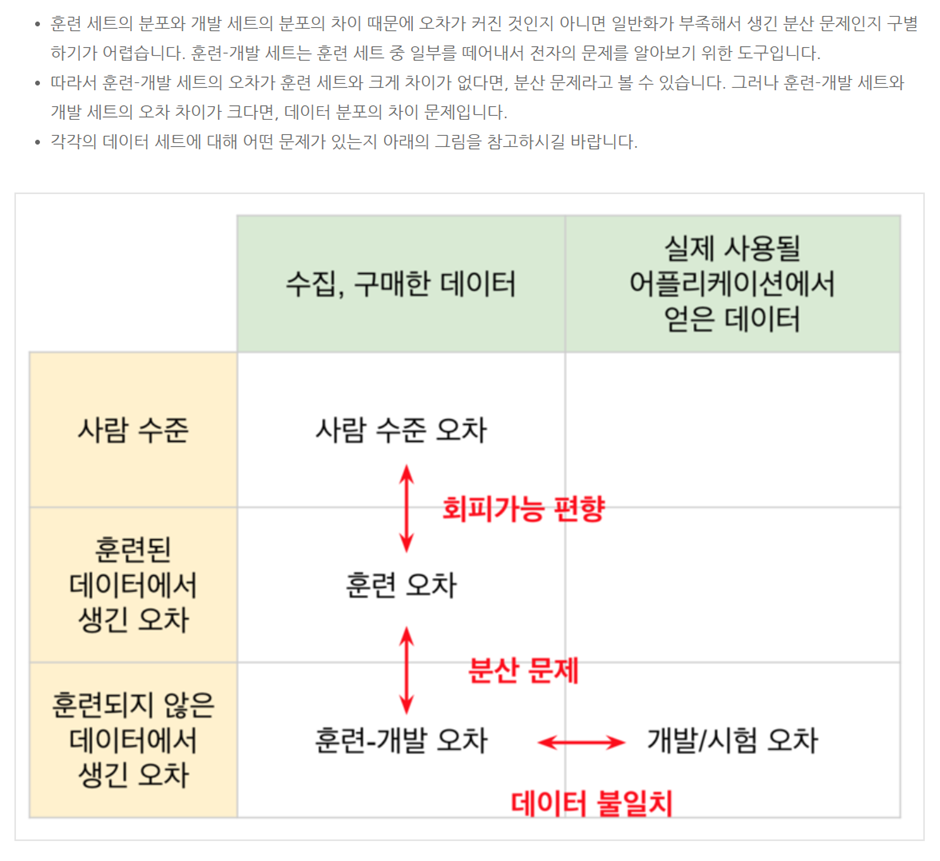
- avoidable bias: bayes error와 training error간의 오차(error)차이
- variance: training error와 dev error간의 오차(error) 차이

bias(데이터 편향) 줄이기: 더 많은 train set을 활용/ 더 오랜 시간 train하는 방법
variance(분산) 줄이기: 정규화(regularization)/ 데이터를 추가
-머신러닝이 사람 수준의 성능을 뛰어 넘는다
EX) 온라인 광고, 제품추천, 유통(시간예측), 대출 승인...
=> 공통점: 구조화된 데이터(structured data)/ 방대한 양의 데이터

- training set: 딥러닝 알고리즘은 train set에서 랜덤한 오류에 대해서 견고한(robust) 특성을 가지고 있다.
- dev/ test set
- dev/ test set을 같은 분포를 유지하도록 조정
- 알고리즘이 옳았던 예와 틀린 예를 고려
- train set와 dev/ test set이 다른 분포를 가질 수 있지만 괜찮다.
- Build your first system quickly, then iterate
- dev/ test set과 metric(평가방법)을 설정
- 빠르게 시스템 구축
- bias/ variance 분석, error분석을 진행
- Data mismatch problem

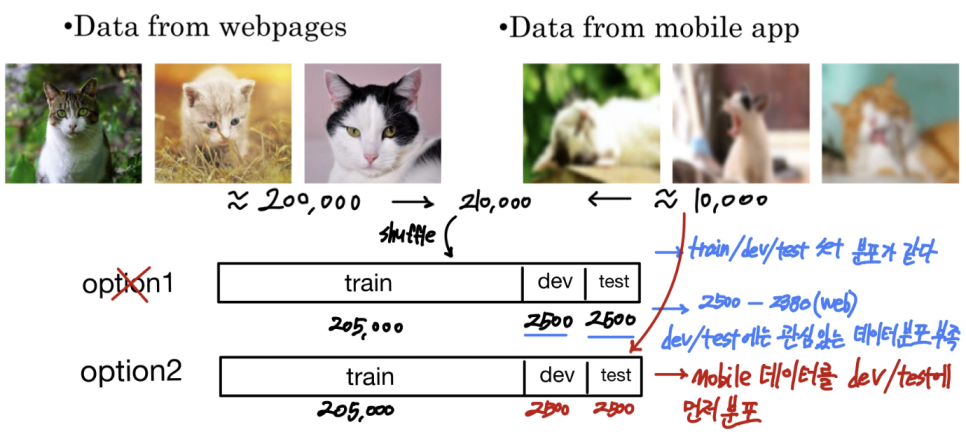

- training-dev set
train set와 동일한 분포를 가지지만, 훈련시키지 않은 데이터
- train set와 dev/ test set간 데이터 분포가 다를경우 해볼만한 시도
1. 오차분석을 통해 train set와 dev/ test set간의 차이를 알아봄
2. training data를 더 유사하게 만들거나, dev test set와 유사한 데이터를 더 많이 수집
- Tranfer learning

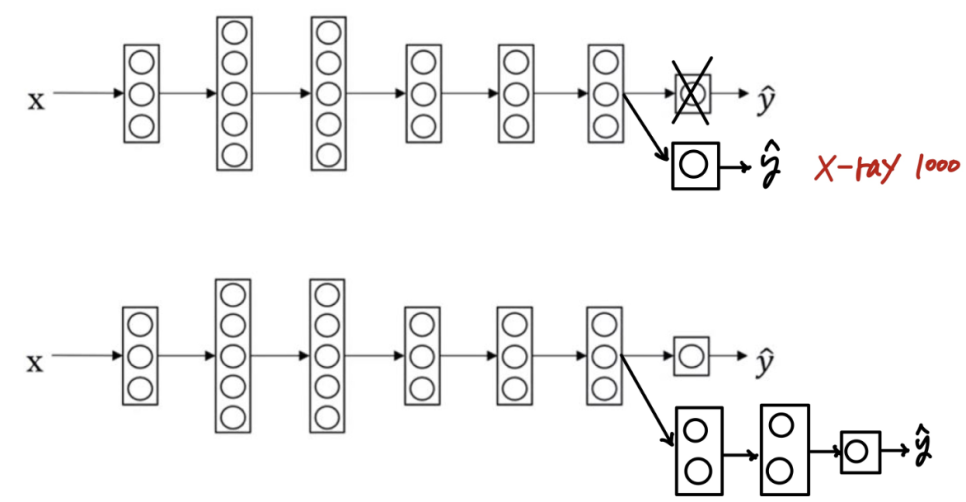
=> 결과적으로 아래와 같은 경우에는 transfer learning을 적용
(알고리즘 A = 전송하는 곳(이전에 훈련한 데이터 세트)/ 알고리즘 B = 전송하려는 곳(새롭게 훈련할 데이터 세트)
1 알고리즘 A와 B가 같은 입력값 x를 가지는 경우
2. 알고리즘 A의 데이터가 B보다 더 많은 데이터를 가지는 경우
3. 알고리즘 A의 low level features가 B에 도움이 되는 경우
- Multi-task learning


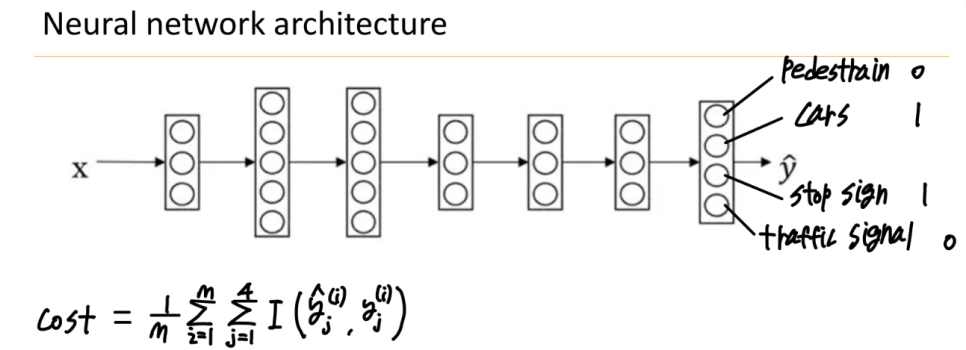
=> single example에 대해서 multi label을 가질 수 있습니다. 이미지에 각각의 클래스에 대해서 복수의 label을 부여할 수 있습니다.
=> 결과적으로 아래와 같은 경우 multi task learning을 적용
1. lower level feature을 공유할 때
2. 일반적으로 각각의 업무에 대해서 데이터 양이 유사한 경우
3. 신경망 네트워크가 충분하게 크다면, multi-task learning의 효율적
- end-to-end learning

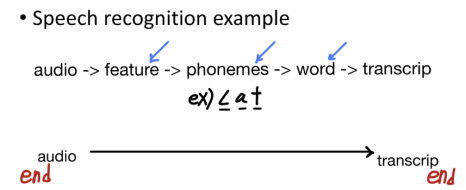
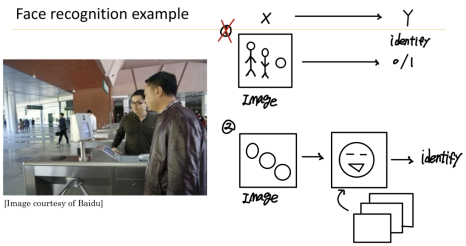
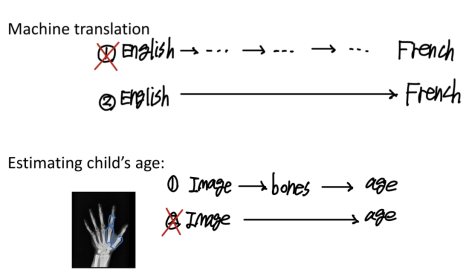
장점
1. 데이터로 하여금 말을 하게함 (사람의 선입견 영향을 덜 받는다)
2. 사람의 중간 요소 설계(hand-designed components)를 줄일 수 있다,
단점
1. 방대한 양의 데이터가 필요
2. 잠재적으로 유용한 사람의 손으로 만들어진 중간 요소를 배제한다.
>>Key Question: end-to-end-learning을 진행할 만큼 충분한 데이터가 있는지가 중요!