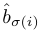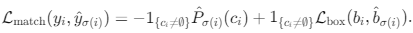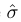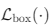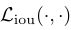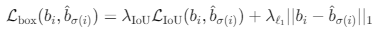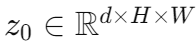- Object Detection을 직접적인 집합 예측 문제(Direct set prediction problem)로 보는 새로운 방법을 제시 - 비최대 억제 절차(non-maximum suppression)나 앵커(anchor) 생성과 같은 수작업 설계 요소를 효과적으로 제거 - Detection pipeline을 간소화한다. - DETR(DEtection TRansformer)라고 불리는 새로운 프레임워크 - 주요 구성 요소는 bipartite matching을 통해 고유한 예측을 강제하는 집합 기반 전역 손실(global loss)과 트랜스포머 인코더-디코더 아키텍처 - 소규모의 고정된 학습 객체 쿼리 세트를 기반으로, DETR은 객체 간 관계와 이미지의 전역적 문맥을 논리적으로 판단하여 병렬로 최종 예측 집합을 직접 출력 - 새로운 모델은 개념적으로 간단하며, 많은 현대 탐지기와 달리 특화된 라이브러리를 필요로 하지 않는다. - DETR은 잘 확립되고 고도로 최적화된 Faster R-CNN을 기반으로 하는 COCO 객체 탐지 데이터셋에서 동등한 수준의 정확도와 실행 성능을 보여준다. - 또한, DETR은 통합된 방식으로 panoptic segmentation을 쉽게 일반화
객체 탐지를 위해 transformer와 bipartite matching을 사용하는 새로운 모델 DETR을 제안 DETR은 기존 방식의 복잡한 구성 요소를 제거하고, 객체 간의 관계와 전역 문맥을 학습하여 병렬적으로 예측
1. Introduction
- Object Detection의 목표는 관심 객체 각각에 대해 Bounding box와 Category labels의 집합을 예측하는 것 - 현대 Detector은 이 집합 예측 문제를 간접적으로 접근하며, 제안된 많은 후보(proposals), 앵커(anchors), 또는 윈도우 중심에 대한 대체 회귀(regression)와 분류(classification) 문제로 정의 - 이 접근 방식은 중복 예측을 통합하는 후처리 단계(postprocessing steps), 앵커 세트 설계(design of the anchor sets), 앵커에 타겟 상자를 할당하는 휴리스틱(the heuristics that assign target box to anchor)에 크게 의존. - 이를 단순화하기 위해, 본 논문에서는 대체 작업을 우회하기 위해 직접적인 집합 예측 접근법을 제안 - 이 "end-to-end" 철학은 객체 탐지에서는 아직 제대로 활용되지 못했다.
Training Pileline
- Object detection을 직접적인 집합 예측 문제(Direct set prediction problem)로 간주하여 training pipeline을 단순화 - 트랜스포머 기반 인코더-디코더(Encoder-Decoder)구조를 채택 - 트랜스포머의 self-attention은 시퀀스 내 모든 요소 간의 상호작용을 명시적으로 모델링하여, 중복 예측을 제거하는 데 적합
DETR(DEtection TRansformer)
- DETR은 모든 객체를 한 번에 예측하며, 예측된 객체(predicted objects)와 실제 객체(GT objects) 간 bipartite matching을 수행하는 집합 손실 함수(set loss function)로 학습 - DETR은 공간적 앵커(spatial anchor)나 비최대 억제(non-maximal suppression)와 같은 수작업으로 설계된 많은 요소를 제거하여 Detection Pipeline을 간소화 - 기존의 대부분 탐지기와 달리, DETR은 특화된 레이어(customized layers)를 필요로 하지 않으며, standard CNN과 트랜스포머 클래스를 포함하는 어떤 프레임워크에서도 쉽게 재현 가능
DETR 작동 원리
- DETR은 일반적인 CNN과 트랜스포머 아키텍처를 결합하여 병렬적으로 최종 탐지 결과를 예측 - 학습 중 bipartite matching을 통해 예측값과 실제 상자 간 고유한 연결을 보장 - 매칭되지 않은 예측은 "no object(객체 없음)" 클래스로 처리
Compared to most previous work
- 기존의 대부분의 direct set prediction 작업과 비교했을 때, DETR의 주요 특징은 bipartite maching loss와 transformer with (non-autoregressive) parallel decoding이다. - 반대로, 이전 연구는 RNN을 사용한 autoregressive decoding에 초점을 맞췄다. - 우리의 matching loss function은 예측값을 실제 객체(ground truth object)에 고유하게 할당하며, 예측된 객체의 순열(permutation)에 대해 불변성을 가진다. 이를 통해 병렬로 예측을 출력할 수 있다.
- DETR은 트랜스포머의 비국소적(non-local) 계산으로 인해 큰 객체에서 특히 더 나은 성능을 나타낸다. - 하지만, 작은 객체에 대해서는 성능이 낮다.
기존 객체 탐지기의 복잡한 요소를 제거하고 트랜스포머를 사용해 객체 간 관계를 학습하는 DETR을 제시 DETR은 병렬적이고 간소화된 detection pipeline으로, Faster R-CNN과 비슷한 성능을 보이며 큰 객체 탐지에서 특히 우수 향후 작은 객체 탐지 성능 개선을 위한 추가 연구가 필요
2. Related work
여러 도메인에 걸쳐 이전 연구를 기반으로 한다.
집합 예측(set prediction)을 위한 bipartite matching loss / 트랜스포머 기반의 Encoder-Decoder architectures / parallel decoding / object detection methods
2.1 Set Prediction(집합 예측)
- 집합을 직접 예측하기 위한 정형화된 딥러닝 모델은 존재하지 않는다. - 기본적인 집합 예측 작업은 다중 라벨 분류(multilabel classification)로, 컴퓨터 비전에서의 기준 접근법인 "one-vs-rest"는 요소 간에 내재된 구조(예: 유사한 경계 상자)를 포함하는 탐지와 같은 문제에 적합하지 않다.
- 이 작업의 첫 번째 어려움은 중복된 예측(near-duplicates)을 방지하는 것이다. - 대부분의 현재 Detector는 비최대 억제(non-maximal suppression)와 같은 후처리 과정(postprcessing)을 사용하여 이 문제를 해결하지만, 직접적인 집합 예측은 후처리가 필요 없는 방식이다. - 이들은 예측된 모든 요소 간의 상호작용을 모델링하는 전역 추론(global inference) 방식이 필요하며, 이는 중복을 피하기 위한 것 - 상수 크기의 집합 예측에서는, 밀집된 완전 연결 네트워크(dense fully connected networks)가 충분하지만 비용이 많이 든다. - 일반적인 접근 방식은 순환 신경망(recurrent neural networks)과 같은 auto-regressive sequence models을 사용하는 것 - 모든 경우에서 손실 함수는 예측의 순열(permutation)에 대해 불변성을 가져야 한다. - 일반적인 해결책은 헝가리안 알고리즘(Hungarian algorithm)을 기반으로 한 손실을 설계하여, 실제 값과 예측값 간의 bipartite matching을 찾는 것 - 이 방법은 순열 불변성(permutation-invariance)을 보장하며, 각 타겟 요소가 고유한 매칭을 갖도록 보장 - 우리는 bipartite matching loss approach를 따른다. - 그러나 대부분의 이전 연구와 달리, 우리는 autoregressive model에서 벗어나 parallel decoding을 사용하는 트랜스포머를 채택
기존 model은 중복 예측을 방지하기 위해 non-maximum suppression과 같은 postprocessing 단계 진행 DETR은 이를 제거한 방식으로 Set Prediction을 수행 Hungarian algorithm을 활용한 bipartite matching loss를 사용하여 target값과 predict값 간 고유한 matching을 보장, transformer와 parallel decoding을 통해 autoregressive model의 한계 극복
2.2 Transformers and Parallel Decoding
- Attention model은 전체 입력 시퀀스에서 정보를 집계하는 신경망 레이어 - 트랜스포머는 self-attention레이어를 도입했으며, 이는 비슷하게 Non-Local Neural Networks와 같이 시퀀스의 각 요소를 스캔하고, 전체 시퀀스에서 정보를 집계하여 업데이트 - Attention-based model의 주요 장점 중 하나는 전역적 계산(global computation) 및 완벽한 메모리(perfect memory)를 제공한다는 점, 이는 긴 시퀀스에서 RNN보다 더 적합하게 만든다
- 트랜스포머는 초기 시퀀스-투-시퀀스(sequence-to-sequence) 모델을 따르며, 자기회귀(auto-regressive) 모델에서 처음 사용 - 이 모델은 출력 토큰을 하나씩 생성했지만, 출력 길이에 비례한 높은 추론 비용(inference cost)과 배치(batch)화의 어려움으로 인해 병렬 시퀀스 생성(parallel sequence generation)의 개발이 이루어졌다. - 트랜스포머와 병렬 디코딩(parallel decoding)을 결합하여 계산 비용과 집합 예측에 필요한 전역 계산 능력 사이의 적절한 균형을 제공
Transformer는 self attention mechanism을 활용해 전역적 정보 집계와 긴 시퀀스 처리에서 RNN을 대체 기존 autoregressive model의 높은 계산 비용 문제를 해결하기 위해 parallel decoding이 도입 DETR은 이를 통해 집합 예측에서 효율적인 계산과 정확성을 동시에 제공합니다.
2.3 Object Detection
- 대부분의 현대 객체 탐지 방법은 초기 추측에 따라 예측을 수행 - Two-stage detectors는 제안된 후보(proposals)에 따라 상자를 예측 - Single-stage methods은 앵커(anchor) 또는 가능한 객체 중심의 그리드(grid)를 기준으로 예측
- 우리의 모델에서는 이러한 수작업 설계를 제거하고, 앵커가 아닌 입력 이미지에 대한 절대 상자 예측(absolute box prediction)을 통해 탐지 과정을 간소화
Set-based loss
- 최근 Detector는 NMS와 함께 실제값과 예측값 간의 non-unique assignment 규칙을 사용 - 학습 가능한 NMS(Learnable NMS) 방법 및 관계 네트워크(relation networks)는 attention을 사용하여 다른 예측 간의 관계를 명시적으로 모델링 - 이들은 direct set losses을 사용하여 post-processing step을 제거하지만, 이러한 방법은 proposal box 좌표와 같은 추가적으로 설계된 문맥 정보를 사용하여 탐지 간의 관계를 효율적으로 모델링 - 반면, 우리는 모델에 인코딩된 사전 지식을 줄이는 솔루션을 찾는다.
Recurrent detectors
- 우리의 접근과 가장 유사한 것은 객체 탐지를 위한 end-to-end set prediction 및 instance segmentation - 이들은 Encoder-Decoder architecture를 기반으로 bipartite-matching loss를 사용하여 CNN activation을 통해 Bounding Box의 집합을 직접 생성 - 그러나 이러한 접근 방식은 소규모 데이터셋에서만 평가되었다. - 특히, 이들은 autoregressive model(정확히는 RNN)을 기반으로 하므로, parallel decoding을 사용하는 최근의 트랜스포머를 활용하지 않는다.
현대 객체 탐지 방법은 Two step 및 One stage 방식으로 나뉘며, 초기 추측에 크게 의존 DETR은 이러한 의존성을 제거하고, Anchor 없이 이미지 자체를 기반으로 탐지 과정을 간소화 기존 탐지 방법은 NMS와 같은 post-processing단계에 의존하거나, 추가 설계된 문맥 정보를 사용 DETR은 이러한 의존성을 줄이고 transformer와 parallel decoding을 활용해 객체 간 관계를 modeling
3. The DETR model
Detection에서 direct set prediction을 위해 2가지 주요 요소가 필요
1. 예측값과 실제 값(GT 값)간 고유한 matching을 강제하는 set prediction loss(집합 예측 손실)
2. 한 번의 처리(single pass)로 객체의 집합을 예측하고, 이들의 관계를 모델링하는 architecture
3.1 Object detection set prediction loss
- DETR은 Decoder를 통해 단일 처리(single pass)로 고정 크기의 N개의 예측을 수행하며, N은 일반적인 이미지 내 객체 수보다 훨씬 크게 설정 - training의 주요 어려움 중 하나는 예측된 객체(클래스, 위치, 크기)와 실제값(ground truth) 간 점수를 매기는 것 - 우리의 loss는 예측값과 실제값 간 최적의 바이파티트 매칭(bipartite matching)을 생성하고, 이후 객체별(bounding box) loss를 최적화한다.
bipartite matching 과정
<Notation> - 객체의 Ground Truth set(실제 객체 집합) - 예측된 객체 집합
- N이 이미지 내 객체 수보다 크다고 가정 - y는 ∅(객체 없음)으로 채워진 N 크기의 집합으로 간주
<Matching cost> - 두 집합 간 비용이 가장 낮은 순열(permutation) σ를 찾는다.
# Matching cost
- class 예측과 예측된 bounding box와 G.T box의 유사성을 모두 고려 - 실제 객체 집합의 각 요소 i를 다음과 같이 표현
- target class label (없을 경우 ∅일 수 있음)
- 중심 좌표(center coordinates), 높이(height), 폭(width)을 정의하는 벡터
- 인덱스 σ(i)를 갖는 예측값에 대해, class Ci의 확률
- 예측된 box
=> 위 Notation을 사용하여 "Matching cost"를 아래와 같이 정의
- 이 Matching 절차는 현대 Detector에서 제안된 후보 또는 앵커를 실제 객체에 매칭하기 위해 사용되는 휴리스틱 할당 규칙과 동일한 역할을 수행 => 하지만 주요 차이점은, 중복 없는 직접 집합 예측을 위해 1:1 매칭을 찾아야 한다는 점
Hungarian Loss
- 이전 단계에서 매칭된 모든 쌍에 대해 계산 Hungarian Loss 수식
- 위의 단계에서 계산된 σ의 최적의 matching
- 실제로, Ci = ∅인 경우 class imbalance를 고려하기 위해 log-probability 항을 10배 낮춘다.
Bounding box Loss
- Matching cost 및 Hungarain loss의 두 번째 구성요소, Bounding box를 평가
- 많은 Detector는 초기 추측값에 대한 편차 Δ로 Bounding box를 예측 - 우리는 Bounding box를 직접 예측 => 구현을 간소화 하지만 loss의 상대적 scaling 문제를 야기한다.
- 가장 일반적으로 사용되는 L1 loss는 작은 box 와 큰 box에 대해 서로 다른 scale을 가지며, 상대적인 오류가 유사하더라도 차이가 발생한다. - 이를 완화하기 위해 L1 loss에 Generalized IoU loss의 linear 결합을 사용 - Generalized IoU loss는 scale-invariant(스케일-불변성)을 갖는다.
- Box Loss
- Hyper parameter
- 두 loss 값은 Batch 내 객체 수로 정규화
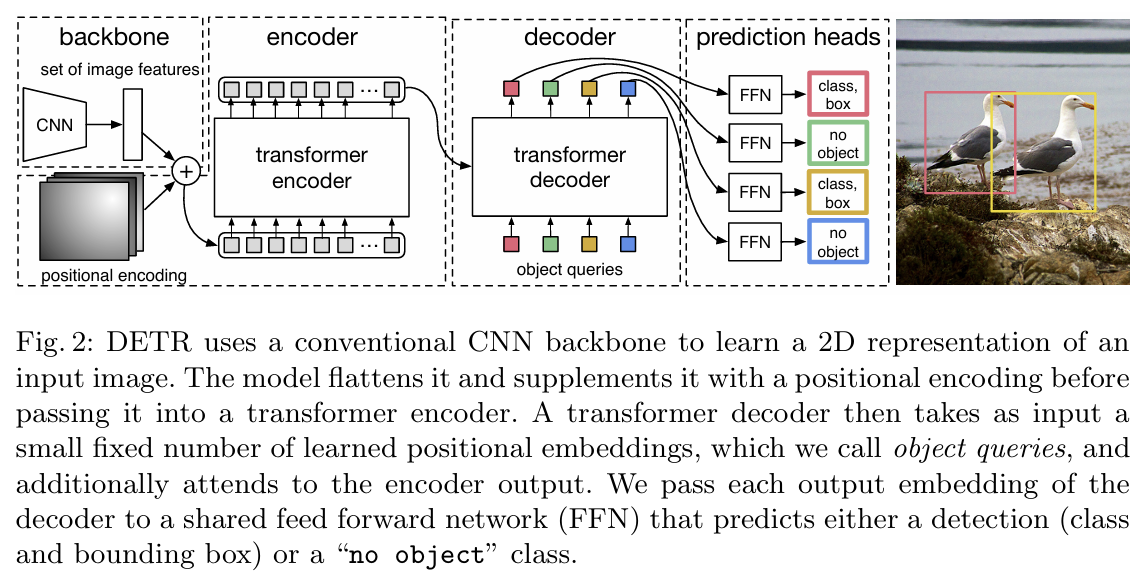
3.2 DETR architecture
- 전체 DETR architecture는 굉장히 단순하다. 다음 3가지 주요 구성 요소를 포함 1. CNN backbone: compact한 feature 표현을 추출 2. Encoder-Decoder transformer: 객체 간 관계를 모델링 3. simple FFN: 최종 Detection 결과를 예측
Backbone
- 입력 이미지를 2D 표현으로 변환 - CNN은 이미지의 주요 특징을 추출하고, 생성된 feature map은 positional encoding과 결합 - 이 결합된 데이터는 Transformer Encoder로 전달
- 초기 이미지(3개의 color channel)에서 시작
- 전통적인 CNN backbone은 낮은 해상도의 activation map을 생성
- 우리가 사용하는 일반적인 값
Transformer encoder
- CNN에서 전달된 입력 feature map의 공간 정보를 축소하여 sequence 형태로 변환 - Multi-head self attention 메커니즘을 통해 객체 간 관계를 모델링
- 첫 번째로 1X1 convolution이 high level activation map F의 channel 차원 C를 작은 차원 d로 줄이며, 새로운 feature map 생성
- Encoder는 입력으로 sequence를 예상하므로, z0의 공간 차원을 하나의 차원으로 병합하여 d X HW feature map을 생성 - 각 Encoder layer는 표준 architecture를 가지며, Multi-head self attention module과 FFN으로 구성 => Transformer architecture는 permutation-invariant를 가지므로, 각 attention layer의 입력에 fixed positional encodings(고정된 위치 인코딩)을 추가하여 보완
Transformer decoder
- 학습된 위치 Embedding(object queries)을 사용하여 입력된 sequence에서 N개의 객체를 병렬로 Decoding - Decoder는 객체와 배경을 구분하고, Decoder 출력은 Prediction Head로 전달
- Decoder는 트랜스포머의 표준 아키텍처를 따르며, Multi-head self-attention과 encoder-decoder attention mechanisms을 사용하여 N개의 size d의 Embedding을 변환
<기존 트랜스포머와의 차이점> - 본 모델은 각 Decoder layer에서 N개의 객체를 병렬로 decoding - 기존은 순차적으로 한 번에 하나의 출력 요소를 예측하는 autoregressive model을 사용
- Decoder 또한 permutation-invariant를 가지므로, N개의 입력 임베딩은 서로 다른 결과를 생성하기 위해 서로 달라야 한다. - 이러한 입력 임베딩은 학습된 위치 인코딩(learnt positional encodings)이며, object queries라고 부른다. - 이 쿼리는 각 attention layer의 입력에 추가
- Decoder는 N개의 object queries를 출력 Embedding으로 변환하며, 이후 FFN 네트워크를 통해 독립적으로 Deconding - Decoding 결과는 박스 좌표와 클래스 레이블로 변환되며, N개의 최종 예측을 생성 - self - and encoder-decoder attention을 사용하여 Decoder는 객체 간의 pair-wise relations를 모델링하며, 이미지 전체를 맥락으로 활용 가능
Auxiliary decoding losses
- 각 Decoder 출력 Embedding은 FFN을 통해 class와 Bounding box를 예측 - "No object(객체 없음)" 클래스를 예측 가능
- Training 중 Decoder에서 보조 손실(auxiliary losses)을 사용하는 것이 유용 - 이는 특히 모델이 각 클래스의 객체 수를 올바르게 출력하도록 돕는 데 효과적= - 우리는 각 Decoder layer 뒤에 Prediction FFNs(Feed-Forward Networks)와 Hungarian loss를 추가 - 모든 Prediction FFNs는 parameter를 공유 - 또한, 각 Decoder layer에서 Prediction FFNs로 입력을 정규화하기 위해 추가적인 공유 레이어 정규화(layer-norm)를 사용
DETR 구조: CNN backbone, Transformer Encoder, Transformer Decoder, FFN으로 구성 CNN은 이미지를 특징 맵으로 변환하며, 트랜스포머는 객체 간 관계를 모델링 FFN은 객체의 클래스와 경계 상자를 예측하며, 필요 시 "No object" 클래스를 사용해 배경을 구분 병렬 처리를 통해 정확하고 효율적인 객체 탐지를 가능하게 한다.