2주차-Supervised Learning
[WEEK2]
Supervised Learning: 입력변수를 사용하여 출력변수의 알려지지 않은 값 또는 미래 값 예측하는 방법-> Labeled training dataset
1. Classification/ 분류(범주형)
1) Binary Classification: pass OR fail
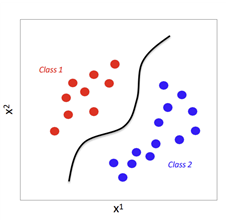
2) Multi-Class Classification: 각 인스턴스 하나의 레이블에 할당
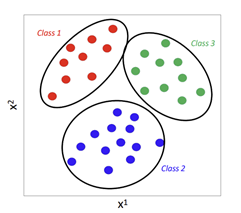
3) Multi-Label Calssification: 각 인스턴스 여러 레이블에 할당 (중복가능)

2. Regression/ 예측(연속형)

Generalization
:Supervised Learning에서 new, unseen data에 대해 정확한 예측 모델 구축
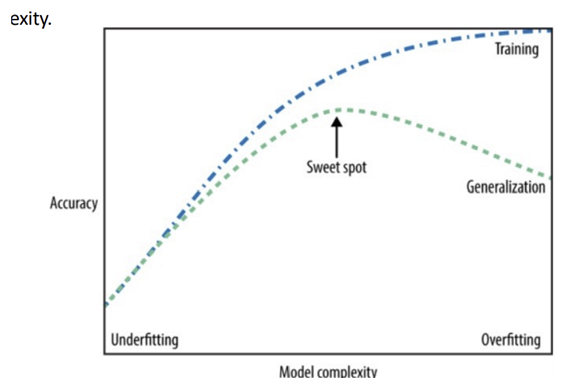
1. Overfitting

-> 가지고 있는 정보의 양에 비해 모델이 너무 복잡함
-> 모델이 training set의 특수성에 너무 적합
-> training set에는 잘 작동하지만, 새 데이터로 일반화할 수 없다.
2. Underfitting

-> 가진 정보의 양에 비해 모델이 너무 간단함.
-> 모델이 데이터의 모든 측면과 변동성을 포착하지 못함.
-> training set에서도 좋지 않을 것이다.
-Model Complexity: training dataset에 포함된 입력의 변화와 밀접한 관련
-> train set에 포함된 데이터 포인트가 다양할수록 Overfitting없이 모델 사용
-> 일반적으로 더 많은 데이터 포인트를 수집하면 더 복잡한 모델 구현 가능
-The trade-off
-Parameters: model 내부 구성
-> 값은 model training을 통해 도출/ 새로운 데이터를 예측하는데 사용
-Hyperparameters: model training을 위한 구성
-> 값은 model training 전에 설정/ model 복잡성과 알고리즘의 동작을 제어

-Training set: model의 parameters학습
-Validation set: model의 hyperparameters 선택
-Test set: model의 generalization능력 최종 평가
-> 조심해야 할 실수 1: training set에 대해서 최종 성능평가
-> 조심해야 할 실수 2: validation set과 test set을 구분하지 않음
Performance Evaluation
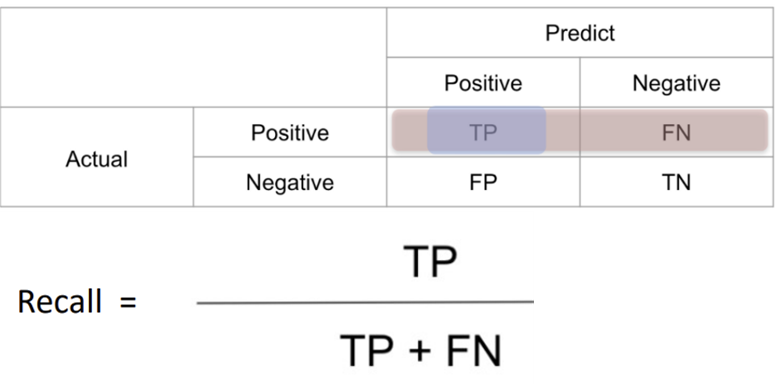
Confusion Matrix
1) Accuracy

2) Precision(정밀도): True라고 예측한 것들 중에 실제 GT가 True인 비율

3) Recall(검출율): GT가 True인 것 중에 실제 True로 예측한 비율
4) F1-score(조화평균)

=> Acc = (5+1000) / (5+100+10+1000) = 0.90
Recall = 5 / (5+100) = 0.05
Precision = 5 / (5+10) = 0.33
F-1 score = 2 * (0.05 * 0.33) / (0.05 + 0.33) = 0.08
-mAP(mean Average Precision)
: 객체감지와 정보 검색 작업에서 성능을 측정하는 데 사용되는 지표
-> Precision과 Recall을 모두 고려하는 지표
EX) 1명을 의심했는데 그 사람이 알고보니 테러범이었다. (그러나 1명의 테러범을 놓쳤다.) -> Precision-UP/ Recall-DOWN
1000명을 의심했는데 그 중에 테러범 2명을 검거했다. (놓친 테러범이 한 명도 없다) -> Precision-DOWN/ Recall-UP
