3-1/Deep Learning
14주차-Natural Language Processing
Donghun Kang
2024. 6. 7. 15:56
- Word Embedding
단어를 밀집 벡터의 형태로 표현하는 방법
- Embedding vector
이 밀집벡터를 word embedding 과정을 통해 나온 결과
- Neural language model

- Context/ Target

- Skip-grams
하나의 단어에서 여러 단어를 예측하는 방법. 즉, 중심단어에서 주변 단어를 예측하는 방식

- Negative sampling
-학습 과정에서 전체 단어 집합이 아니라 일부 단어 집합에만 집중할 수 있도록 하는 방법.
-주변 단어들을 긍정(positive), 랜덤으로 샘플링된 단어들을 부정(negative)으로 레이블링
-context와 word의 관계에 있어서, 1개의 양성(positive) target을 제외한 나머지 text에 대해서는 음성(negative)으로 설정


- Sentiment Classification

=> "good" 단어에만 집중해서 높은 평점을 부여할 수 있다.
- RNN for sentiment classification

- Addressing bias in word embeddings
EX)

=> Embedding은 성별, 나이, 종교 등을 고려해서 모델을 훈련할 수 있지만, 이들의 편향성(bias)을 제거하지 않고 모델을 훈련하면, 편향된 모델을 만들 수 있기에 이를 해소할 필요가 있다.

- Sequence to sequence model
n번째 예측값을 n+1번째 입력 데이터와 함께 n+1번째 예측에 활용
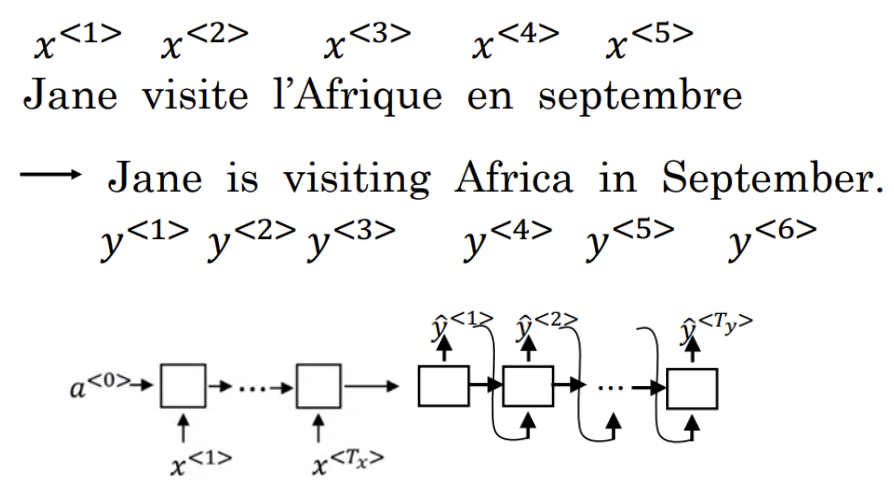

- Machine translation as buliding a conditional language model

- Finding the most likely translation

- Greedy search
단순하게 해당 시점에서 가장 확률이 높은 후보를 선택하는 것.
시간 복잡도 면에서는 훌륭한 방법이지만, 최종 정확도 관점에서는 좋지 못한 방법.

Q) Greedy search말고 Beam search를 사용하는 이유는?
A) Greedt search는 특정시점에서 확률 분포상 무조건 가장 큰 예측값에만 관심이 있을뿐이다.
(1등과 2등의 차이가 정말 미묘하다면, 2등이 정답일 경우도 고려해야함.)
Beam search는 Beam의 개수만큼을 골라서 이를 고려하여 예측한다.
- Beam search
해당 시점에서 Beam의 개수만큼 골라서 진행하는 방식.
Beam 범위 내에서 확률이 높은 결과값을 가져온다.
B=3(beam width) : 3등까지 본다.


- Beam search - refinements

- Error analysis on beam search


- Beam search가 더 많으면 : Beam의 폭을 늘린다.
- RNN이 더 많으면 : 정규화를 추가, training data 증가, 다른 network architecture시도
- Attention model
기존에 하나씩 입력값을 훈련하는 것에서, attention weight 설정에 따라 여러 개의 입력값을 훈련.
하나의 입력에서 여러 개의 입력을 한번에 받아서 훈련


