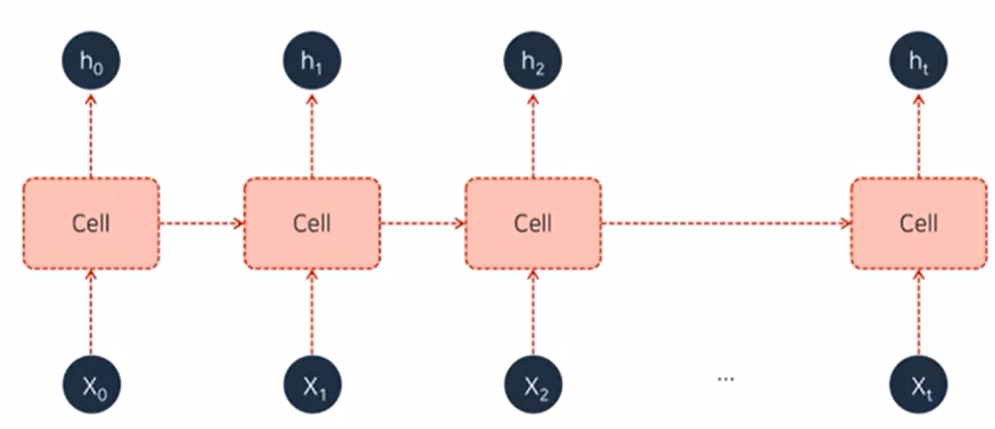
- RNN(Recurrent Neural Network)

- sigmoid: 기울기 작아 더 빨리 "0"으로 소실. (Vanishing Gradient)
- tanh: "0"으로 가는건 같지만 기울기 커 sigmid보단 느리게 "0"으로 간다.
- Vanilla RNN: 초기의 RNN 형태


RNN 모델의 가중치는 모든 Cell에 대해 동일
- Back Propagation Through Time(BPTT)

- 1보다 작은 값들이 많이 곱해진다, "0"으로 update
=> 단 주기에는 괜찮지만 주기가 길어지면 "Vanishing/ Exploding Gradient"문제가 발생
=> 결국 학습이 잘 되지 않는다.
- LSTM(Long Short Term Memory)


- (Cell) State: 장기기억
- (Hidden) State: 단기기억
- Xt: 현재
- Forget Gate

- 중요한 정보라면 sigmoid 함수에서 "1"에 가까운 값을 곱해줌
=> 정보를 최대한 살려준다.
- 중요하지 않은 정보라면 sigmoid 함수에서 "0"에 가까운 값을 곱해줌
=> 장기기억에 거의 반영하지 않는다.
- Input Gate

- 현재 시점의 정보 이전에 학습된 정보와 결합되어 sigmoid함수를 거쳐 중간부분에 임시 저
- Cell State
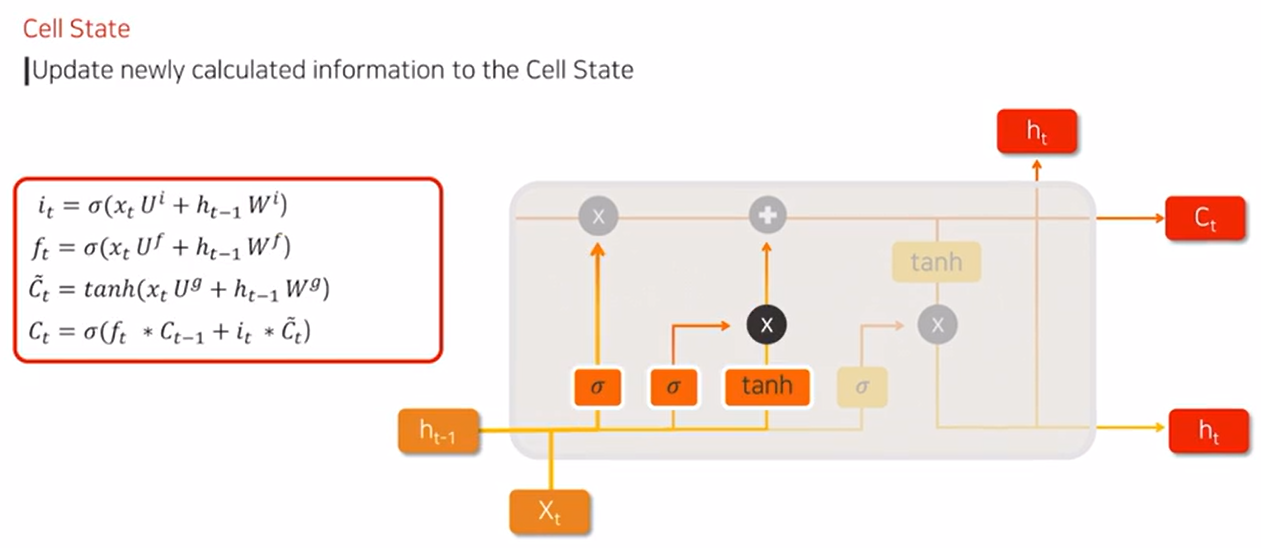
- sigmoid(0~1), tanh(-1~+1) 계산하여 장기기억 cell에 저장
- Output Gate

- Cell state: 장기기억
- Hidden state: 단기기억
- LSTM 모델링

- 기본 입출력 shape
nn.LSTM(input_size=10, hidden_size=20, num_layers=1, bidirectional=False, batch_first=True)- input_size: featue의 개수, 특성(colum개수)
- hidden_size: 특성 추출 (적절하게 설정)
- num_layers: LSTM stacking(적층) 개수
- bidirectional: 순방향으로 학습(False), 순방향, 역방향 모두 학습(True)
- batch_first: output에서 batch_size가 먼저 나오게하는 옵션(True)

EX1)
nn.LSTM(input_size=10, hidden_size=20, num_layers=1, bidirectional=False, batch_first=True)inputs = torch.zeros(1, 35, 10)
# batch_size, sequence_length(= window_size), number of featurestorch.Size([1, 35, 20]) #output
torch.Size([1, 1, 20]) #hidden_state
torch.Size([1, 1, 20]) #cell_state
EX2) num_layers 변경
nn.LSTM(input_size=10, hidden_size=20, num_layers=2, bidirectional=False, batch_first=True)inputs = torch.zeros(1, 35, 10)
# batch_size, sequence_length(= window_size), number of featurestorch.Size([1, 35, 20]) #output
torch.Size([2, 1, 20]) #hidden_state
torch.Size([2, 1, 20]) #cell_state
EX3) bidirectional = True 변경
nn.LSTM(input_size=10, hidden_size=20, num_layers=2, bidirectional=True, batch_first=True)inputs = torch.zeros(1, 35, 10)
# batch_size, sequence_length(= window_size), number of featurestorch.Size([1, 35, 40]) #output
torch.Size([4, 1, 20]) #hidden_state
torch.Size([4, 1, 20]) #cell_state
'SK AI Data Academy 1기 중급 > [SK에코플랜트] AI모델을 활용한 철근 단가 예측' 카테고리의 다른 글
| 손실함수(Huber Loss) (0) | 2024.07.04 |
|---|---|
| 라이브러리 목록&시계열 데이터 전처리&정규화, 표준화 (0) | 2024.07.04 |