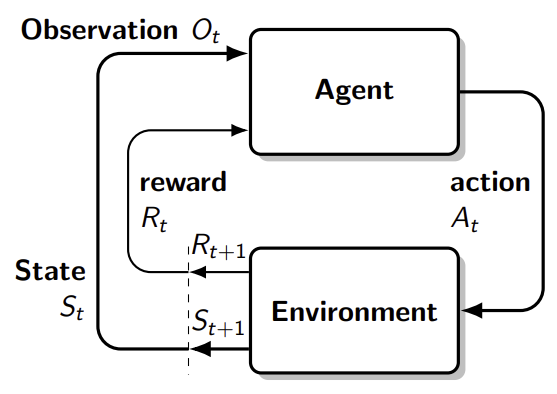
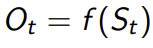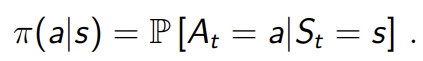- Agent: 강화학습에서 학습을 수행하는 주체 - Environment: 에이전트가 상호작용하는 공간이나 시스템 - State: 에이전트가 인식하는 환경의 현재 상태 - Action: 에이전트가 환경에 대해 취하는 행동 - Reward: 에이전트가 행동의 결과로 받는 피드백 - Observation: 에이전트는 환경에서 특정 데이터를 관찰하고, 이를 바탕으로 다음 행동을 결정
주요 특징
1. No supervisor: 정답 레이블이 제공되지 않고, 에이전트가 보상만을 기반으로 학습.
2. Data-driven: 데이터 기반
3. Discrete time space: 이산적인 시간 단계
4. Sequential data scream: 데이터가 순차적으로 제공
5. Agent actions affect subsequent data: 에이전트의 행동은 이후의 데이터에 영향
에이전트가 행동을 실행하고, 관찰과 보상을 받기까지 한 단계의 시간 지연이 있다고 가정
Agent는 매시간 t마다
Environment는 매시간 t마다
강화(reinforcement)의 정의
강화는 특정 행동이 선행 자극에 의해 강화되어 미래에 더 자주 발생하게 하는 결과를 의미합니다. 위키피디아에 따르면, 강화의 네 가지 유형이 있다: 긍정적 강화(positive reinforcement), 부정적 강화(negative reinforcement), 소거(extinction), 벌(punishment)
학습(learning)의 정의
학습은 지식과 기술을 습득하여 미래의 문제나 기회를 이해하고 해결할 수 있도록 준비하는 과정
Reward(보상)
- Reward(보상) R은 scalar feedback signal(스칼라 피드백 신호) - Reward는 에이전트가 주어진 시간 단계에서 얼마나 잘 수행하고 있는지를 나타냄 - Reward는 일반적으로 실수 또는 정수로 간주 - 에이전트의 목표는 시간이 지남에 따라 보상을 극대화 하는 것
모든 목표는 기대되는 누적 보상의 극대화로 설명될 수 있다.
EX)
- 팬케이크 뒤집기:
Pos. reward: 180도 회전한 팬케이크를 성공적으로 잡을 때.
Neg. reward: 팬케이크를 바닥에 떨어뜨릴 때.
- 주식 거래:
reward: 거래 포트폴리오의 금전적 가치
- 아타리 게임
reward: 게임 에피소드 끝에서의 최고 점수
- 자율 주행 자동차
Pos. reward: 충돌 없이 A에서 B로 안전하게 이동.
Neg. reward: 다른 차, 보행자, 자전거 등을 치는 경우.
- 클래식 제어 과제
Pos. reward: 주어진 참조 궤적을 정확하게 따를 때.
Neg. reward: 시스템 제약을 위반하거나 큰 제어 오류를 범할 때.
보상의 특성
1. 행동은 단기적 및 장기적인 결과를 가질 수 있다.
- 보상지연: 어떤 행동에 대한 보상은 즉각적으로 주어지지 않을 수 있다.
EX) 주식거래, 전략 보드 게임
2. 보상의 긍적적 및 부정적인 값
- 어떤 상황에서는 부정적인 보상이 주어질 수 있다.
EX) 차가 벽에 부딪힐 때
3. 보상의 확률적 요소
- 외부 요인으로 인해 보상이 확률적으로 변할 수 있다.
EX) 바람이 자율 헬리콥터를 나무에 부짖치게 함
강화학습은 시간에 따른 보상 분포와 밀접한 관련이 있다. => 적절한 보상 함수 설계가 필요함
EX)
"보상 함수는 당신이 요청한 것을 정확하게 제공합니다. 그러나 당신이 요청했어야 했던 것이나 당신이 의도한 것을 제공하지는 않습니다."
Episodic tasks(에피소딕 과제)
- 자연스럽게 하위 시퀸스로 나뉘는 문제 (finite horizon)(유한한시간) EX) 대부분의 게임, 미로
- 반환은 유한 합으로 나타난다.
- 에피소드가 종료되는 시점:
Counting tasks(지속적 과제)
- 자연스러운 종료가 없는 문제 (infinite horizon)(무한한 시간) EX) 프로세스 제어 작업 - 반환은 무한합이며 무한대로 가지 않기 위해 discounted 되어야 한다.
- discount rate:
Discounted Rewards
- Numeric viewpoint
- Strategic viewpoint
- Mathematical options
현재 return은 discounted된 미래 return으로 계산된다.
History
과거의 모든 관찰, 행동, 보상 시퀸스를 포함한다.
State
History의 함수로 정의된다.
현재의 상태는 과거의 모든 정보를 기반으로 결정된다.
Environment state
- 환경의 내부 표현:
EX) 물리적 상태: 자동차의 속도, 모터의 잔류/ 게임 상태: 체스 보드의 현재 상황/ 금융 상태: 주식 시장의 형태
- 에이전트가 관찰할 수 있는 상태는 일반적으로 환경 상태의 함수로 나타난다.
- Continuous(연속적) 또는 Discrete(이산적)일 수 있다.
Agent state
- 에이전트의 내부 표현:
=> 일반적으로 Agent state와 Environment state는 같지 않다.(측정 오류나 에이전트의 추가적인 메모리와 같은 이유때문)
- 에이전트의 상태는 다음 행동에 필요한 중요한 요약된 정보를 포함함.
- 내부 지식과 정책 표현에 의존
- Continuous(연속적) 또는 Discrete(이산적)일 수 있다.
- History 함수로 표현 가능
Information state
- "미래는 현재를 알면 과거와 독립적(independent)이다."
- State가 주어지면 history는 더 이상 필요없다.
- Environment state는 Markov 특성을 가진다.
- History도 Markov 특성을 가진다.
EX) Rat Example
Q) What if agent state
A)
1. 마지막 세 항목으로 정의할 경우: 감전으로 예상
2. 불빛, 종, 레버의 발생 횟수로 정의할 경우: 치즈로 예상
3. 전체 시퀴스로 정의할 경우
Agent의 상태를 어떻게 정의하느냐에 따라 학습과정과 성능이 달라질 수 있다.
Fully Observable Environments(완전 관찰 환경)
- Fully Observability
Agent가 Environmnet state를 directly(직접적으로) 관찰할 수 있다. => Agent는 Environmnet의 모든 state정보를 완전하게 인식할 수 있다.
=> Markov decision process(MDP) 으로 모델링
Partially Observable Environments(부분 관찰 환경)
- Partial Observability
Agent가 Environmnet state를 indirectly(간접적으로) 관찰할 수 있다. => Environment의 일부 정보만 관찰할 수 있으며, 전체 state는 알 수 없다. EX) 카메라 비전을 가진 로봇은 절대 위치를 알지 못함/ 거래 에이전트는 현재 가격만 관찰
=> Partially Observable Markov Decision Process(POMDP) 으로 모델링
Agent는 스스로 상태를 구성해야 한다:
Major Components of an RL agent
1. Policy: Agent의 행동을 결정하는 함수
2. Value function: 각 상태 또는 행동이 얼마나 좋은지 평가하는 함수
3. Model: Agent가 환경을 표현하는 방식
Action
Agent가 보상을 극대화하기 위해 선택하는 자유
Finite Action Set(FAS): 제한된 수의 행동 옵션이 있다.
Continuous Action Set(CAS): 무한한 수의 행동이 가능함.
- Deterministic일 수도 있고, Random Variable일 수도 있다.
=> Action은 종종 state에 의존하며, 제한될 수 있다.
EX)
블랙잭 게임에서 카드를 선택하는 것은 유한 행동 집합(FAS)에 속한다/ 자율 주행 자동차를 운전하는 것은 연속 행동 집합(CAS)에 속한다/ 주식 포트폴리오에서 옵션을 구매하는 것은 유한 또는 연속 행동 집합(FAS/CAS) 모두 가능하다.
새로운 강화 학습 문제를 해결할 때 상태 공간과 행동 공간을 평가하는 것이 매우 중요 특히, 행동이 유한한지 연속적인지 파악하는 것은 적절한 해결 알고리즘을 선택하는 첫 번째 단계이다.