- 서로 다른 행의 비교나 연산을 위해 만든 함수 - GROUP BY를 쓰지 않고 그룹 연산 가능
* PARTITION BY, ORDER BY, ROWS...절 전달 순서 중요(ORDER BY를 PARTITION BY절 전에 사용 불)
그룹 함수의 형태
- OVER절을 사용하여 윈도우 함수로 사용 가능 - 반드시 연산할 대상을 그룹함수의 입력값으로 전달
순위 함수
1. RANK: 순위를 매기면서 같은 순위가 존재하면 존재하는 수만큼 건너 뛴다.
2. DENSE_RANK: 순위를 매기면서 같은 순위가 졵재하더라도 다음 순위를 건너뛰지 않고 이어서 매긴다.
3. ROW_NUMBER: 순위를 매기면서 동일한 값이라도 각기 다른 순위를 부여한다.
순위 함수
EX)
RANK
1, 2, 2, 4, 5, 5, 7 ...
DNESE_RANK
1, 2, 2, 3, 4, 4, 5 ...
ROW_NUMBER
1, 2, 3, 4, 5, 6, 7 ...
집계 함수
1. SUM: 데이터의 합계를 구하는 함수, 인자값으로는 숫자형만 올 수 있다.
2. MAX: 데이터의 최댓값을 구하는 함수
3. MIN: 데이터의 최솟값을 구하는 함수
4. AVG: 데이터의 평균값을 구하는 함수
5. COUNT: 데이터의 건수를 구하는 함수
# 윈도우 함수의 연산 범위
BETWEEN A AND B
- 시작점 정의
범위
의미
CURRENT ROW
현재행부터
UNBOUNDED PRECEDING
처음부터(DEFAULT)
n PRECEDING
n 이전부터
- 마지막 시점 정의
범위
의미
CURRENT ROW
현재행까지(DEFAULT)
UNBOUNDEDFOLLOWING
마지막까지
n FOLLOWING
n 이후까지
- ROW / RANGE
기준
의미
ROWS
- 값이 같더라도 각 행씩 연산 - 행 자체가 기준
RANGE
- 같은 값의 경우 하나의 RANGE로 묶어서 동시 연산(DEFAULT) - 행이 가지고 있는 데이터 값이 기준
행 순서 함수
1. FIRST_VALUE: 파티션 별 가장 선두에 위치한 데이터를 구하는 함수
2. LAST_VALUE: 파티션 별 가장 끝에 위치한 데이터를 구하는 함수
3. LAG: 파티션 별 특정 수만큼 앞선 데이터를 구하는 함수
4. LEAD: 파티션 별 특정 수만큼 뒤에 있는 데이터를 구하는 함수
비율 함수
1. RATIO_TO_REPORT: 파티션 별 합계에서 차지하는 비율을 구하는 함수
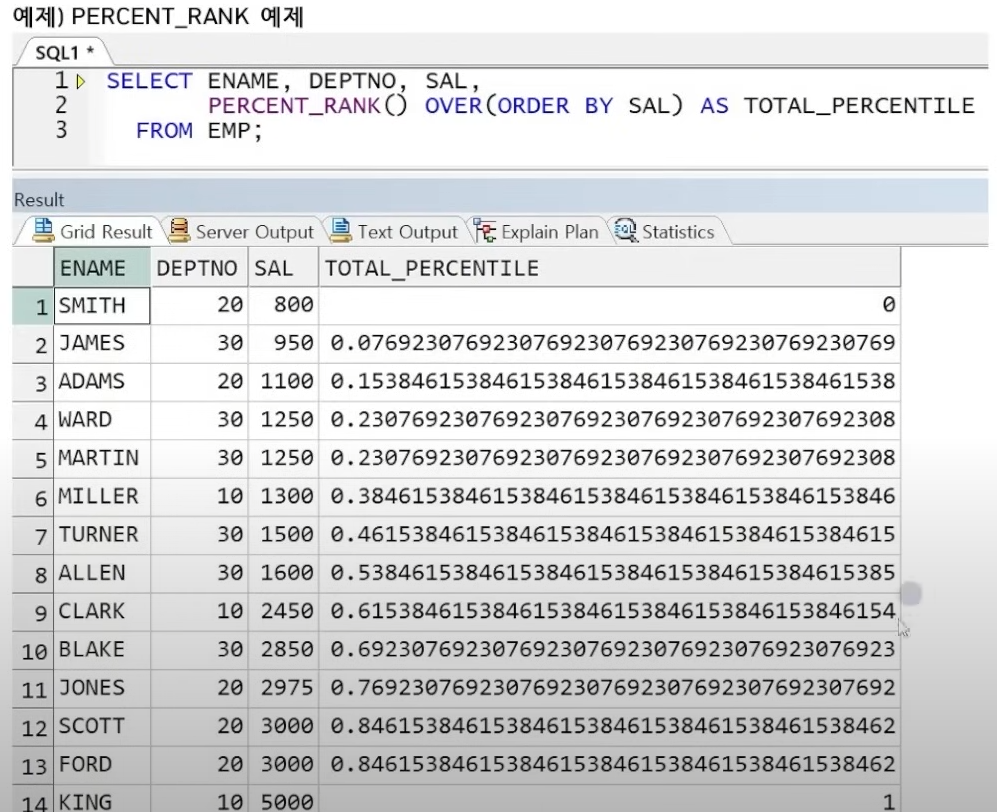
2. PERCENT_RANK: 해당 파티션의 맨 위 끝 행을 0, 맨 아래 끝 행을 1로 놓고 현재 행이 위치하는 백분위 순위 값을 구하는 함수
3. CUME_DIST: 해당 파티션에서의 누적 백분위를 구하는 함
2-13. TOP-N 쿼리
TOP-N QUERY
- 전체 결과에서 특정 N개 추출
추출 방법
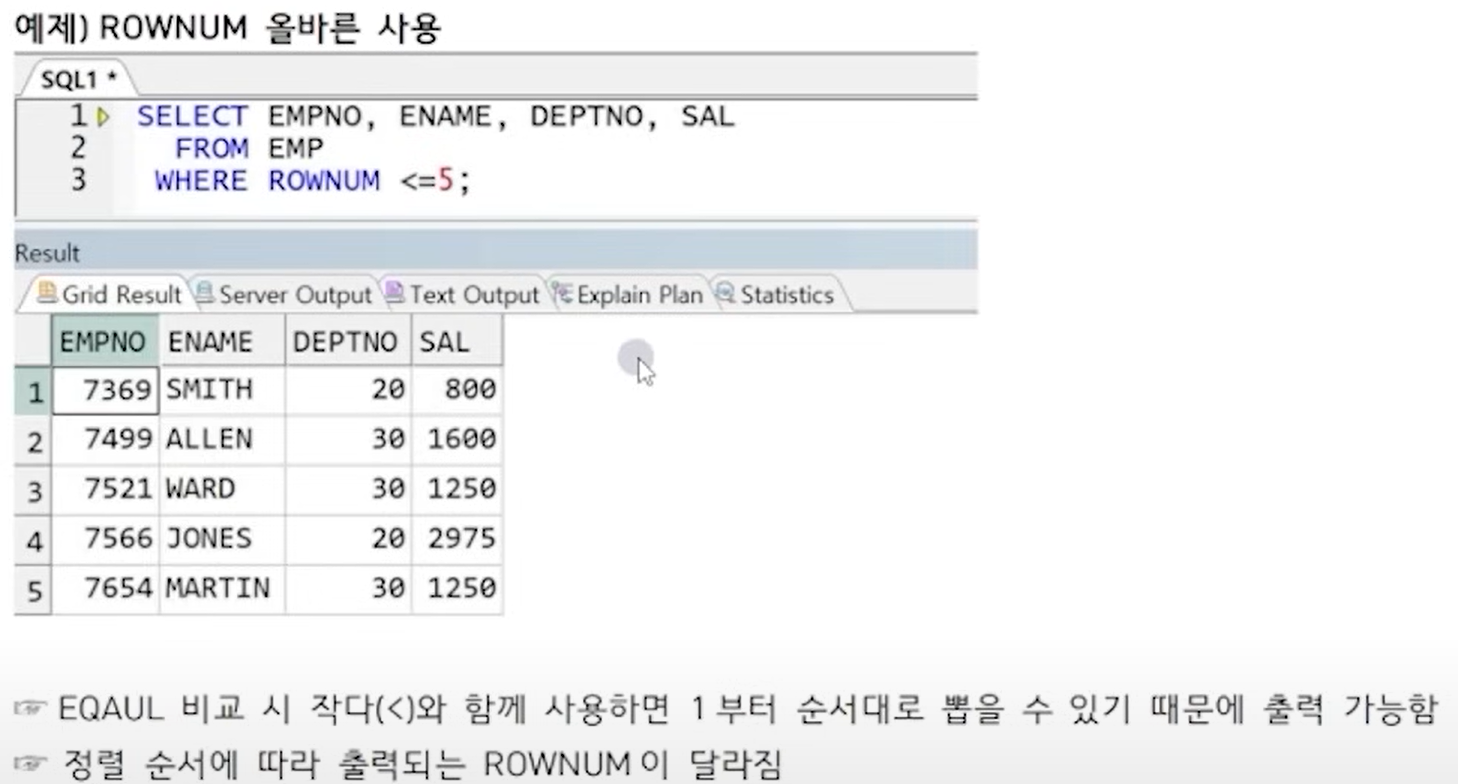
ROWNUM
- 출력된 데이터 기준으로 행 번호 부여 - 절대적인 행 번호가 아닌 가상의 번호이므로 특정 행을 지정할 수 없다.('=' 연산 불가) - 첫번째 행이 증가한 이후 할당되므로 '>' 연산 사용 불가(0은 가능)
FETCH절
- 출력될 행의 수를 제한하는 절 - ORACLE 12C 이상부터 제공(이전 버전에는 ROWNUM 주로 사용) - SQL-Server 사용 가능 - ORDER BY절 뒤에 사용(내부 파싱 순서도 ORDER BY 뒤)
- OFFSET: 건너뛸 행의 수
- N: 출력할 행의 수
- FETCH: 출력할 행의 수를 전달하는 구문
- FIRST: OFFSET을 쓰지 않았을 때 처음부터 N행 출력 명령
- NEXT: OFFSET을 사용했을 경우 제외한 행 다음부터 N행 출력 명령
- ROW | ROWS: 행의 수에 따라 하나의 경우 단수, 여러값이면 복수형(특별히 구분하지 않아도 됨)
2-14. 계층형 질의
계층형 질의
- 하나의 테이블 내 각 행끼리 관계를 가질 때, 연결고리를 통해 행과 행 사이의 계층을 표현하는 기법 - PRIOR의 위치에 따라 연결하는 데이터가 달라짐 ** START WITH: 데이터를 출력할 시작 지정하는 조건 ** CONNECT BY PRIOR: 행을 이어나갈 조건 ** NOCYCLE: 순환이 발생하면 무한 루프가 될 수 있기 때문에 이를 방지하고자 사
ORDER SIBLINGS BY를 사용하여 같은 레벨일 경우 DNAME 오름차순으로 정렬1000번 직원의 매너지는 2000번 사윈인데, 2000번 사원도 1000번 직원의 매니저이다. => ERROR발정상 출력
2-15. PIVOT과 UNPIVOT
데이터의 구조
1. LONG DATA(Tidy data): 하나의 속성이 하나의 컬럼으로 정의되어 값들이 여러 행으로 쌓이는 구조
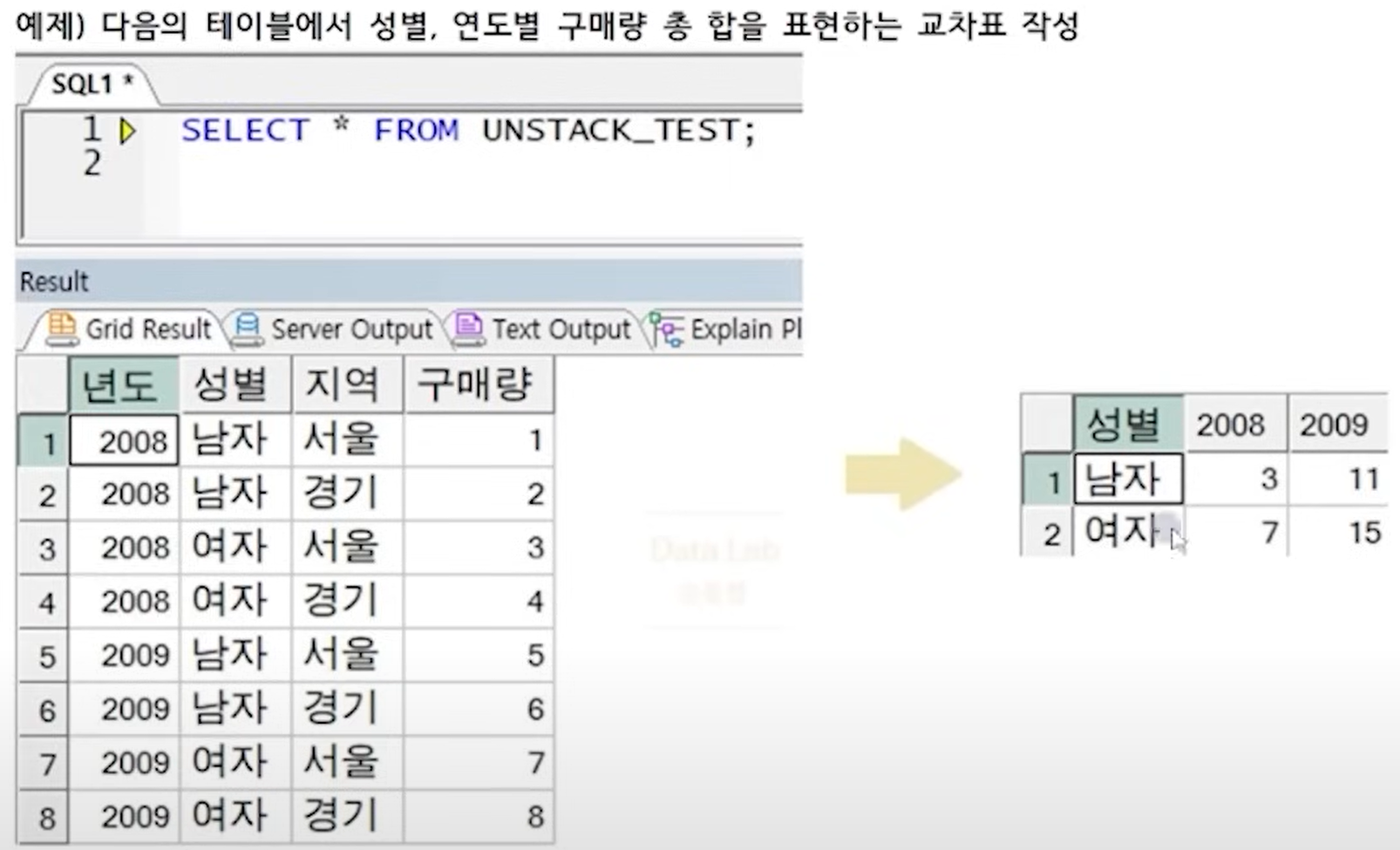
2. WIDE DATA(Cross table): 행과 컬럼에 유의미한 정보 전달을 목적으로 작성하는 교차표
데이터 구조 변경
1. PIVOT: LONG => WIDE
2. UNPIVOT: WIDE => LONG
PIVOT
- 교차표를 만드는 기능 - FROM절에 STACK, UNSTACK, VALUE 컬럼명만 정의 필요 - PIVOT절에 UNSTACK, VALUE 컬럼명 정의 - PIVOT절 IN 연산자에 UNSTACK 컬럼 값을 정의
EX)
UNPIVOT
- WIDE 데이터를 LONG 데이터로 변경하는 문법 - STACK컬럼: 이미 UNSTACK되어 있는 여러 컬럼을 하나의 컬럼으로 STACK시 새로 만들 컬럼이름(사용자 정의) - VALUE컬럼: 교차표에서 셀 자리(VALUE)값을 하나의 컬럼으로 표현하고자 할 때 새로 만들 컬럼명(사용자 정의) - 값1, 값2: 실제 UNSACK되어 있는 컬럼 이름들
EX)
2-16. 정규표현식
정규 표현식
- 문자열의 공통된 규칙을 보다 일반화 하여 표현하는 방법 - 정규 표현식 사용 가능한 문자함수 제
EX)
REGEXP_REPLACE
- 정규식표현을 사용한 문자열 치환 가능
특징
1. 바꿀 문자열 생략 시 문자열 삭제
2. 검색 위치 생략 시 1
3. 발견횟수 생략 시 0(모든)
옵션
- c: 대소를 구분하여 검색
- i: 대소를 구분하지 않고 검색
- m: 패턴을 다중라인으로 선언 가능
EX)
숫자를 모두 삭제
REGEXP_SUBSTR
- 정규 표현식을 사용한 문자열 추출 - 옵션은 REGEXP_SUBSTR과 동일
특징
1. 검색위치 생략 시 1
2. 발견횟수 생략 시 1
3. 추출 그룹은 서브패턴을 추출 시 그 중 추출할 서브패턴 번호
EX)
REGEXP_INSTR
- 주어진 문자열에서 특정 패턴의 시작 위치를 반환 - 옵션은 REGEXP_SUBSTR과 동일
특징
1. 시작위치 생략 시 처음부터 확인 (기본값: 1)
2. 발견횟수 생략 시 처음 발견된 문자열 위치 리턴
EX)
REGEXP_LIKE
- 주어진 문자열에서 특정 패턴을 갖는 경우 반환(WHERE절 사용만 가능) - 옵션 REGEXP_REPLACE와 동일