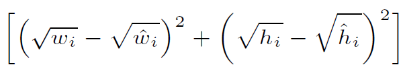- 인간의 시신경을 모방하여 만들어짐 - DNN의 문제점에서 부터 출발 => DNN은 기본적으로 1차원 형태의 데이터를 사용/ 2차원 이미지가 입력값이 되는 경우, 이를 이것을 flatten 시켜 한 줄의 데이터로 만드는데 이 과정에서 공간적, 지역적 정보가 손실된다.
- CNN은 이미지를 그대로 받아 공간적, 지역적 정보를 유지한 채 특성들의 계층을 빌드업한다. => 이미지 전체보다는 부분을 본다, 이미지의 한 픽셀과 주변 픽셀들의 연관성을 살린다.
Background
Convolution
- input: d1 X d2 - Filter: k1 X k2 => Output: (d1-k1+1) X (d2-k2+1)
Zero Padding
- Edge(테두리)를 0으로 구성해 손실 값을 없애준다.
Stride
- 필터를 얼마만큼 움직일 것인가.
- input: d1 X d2 - Filter: k1 X k2 - Stride: 1 => Output: (((d1-k1) / s) +1) X (((d2-k2) / s)+1)
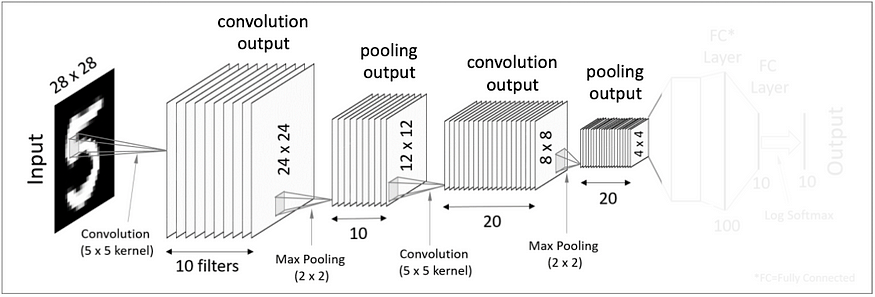
전체적인 구조
- CNN은 Convolution Layer와 Polling Layer들을 Activation Function 앞뒤로 배치하여 만들어 진다.
1. First Convoluiton Layer
- input: 28X28크기의 이미지 - 여러개의 필터(커널)을 사용하여 output을 얻는다. - 28X28 이미지 입력값에 10개의 5X5 필터를 사용하여 10개의 24X24 matrics, Conv 결과값을 만든다. - 그 후 이렇게 도출된 결과값에 Activation Function을 적용한다. => A Convolution Layer = convolution + activation
2. First Pooling Layer
Pooling
- Convolution 과정에서 많은 수의 결과값들이 생성 - 위와 같이 한개의 이미지에서 10개의 이미지 결과값이 도출 => 즉 correlation(연관성)이 낮은 부분은 결과값에 크기를 줄이는(Dimension) 과정 EX) Max pooling, Average pooling
- Pooling Layer의 결과값이 10개의 12X12 matrics가 된다.
3. Second Convolution Layer
- 이번 Conv Layer에서는 Tensor Convolution을 적용 - 이전의 Pooling Layer에서 얻은 12X12x10 tensor를 대상으로 5X5X10 크기의 tensor filter 20개를 사용 - 8X8크기의 결과값 20개를 얻는다.
4. Second Pooling Layer
- 전의 Pooling 과정과 동일한 방식으로 진행한다. - 4X4크기의 결과값 20개를 얻는다.
5. Flatten(Vectorization)
- 4X4X20의 tensor를 일자 형태의 데이터로 쭉 펼친다고 생각하자 - 각 세로줄을 일렬로 쭉 세운다. - 이는 320차원을 가진 vector 형태가 된다.
6. Fully-Connected Layers(Dense Layers)
- 하나 혹은 하나 이상의 Fully-Conncted Layer을 적용 - 마지막에 softmax activation function을 적용
7. Learnable parameters
- parameter: 모델 내부에 있으며 데이터로부터 값이 추정될 수 있는 설정 변수 - hyper parameter: 모델 외부에 있으며 데이터로부터 값이 추정될 수 없는 설정 변
1. 이미지 전체를 한번만 본다. => R-CNN은 이미지를 여러장으로 분할하고, CNN 모델을 이용하여 이미지를 분석 2. 통합된 모델을 사용한다. (One-stage detection) => 기존의 Object Detection 모델은 다양한 전처리 모델과 인공 신경망을 결합하여 사용 3. 주변 정보까지 학습하여 이미지 전체를 처리하여 background error가 적다. => 이미지 전체를 처 4. 실시간으로 객체를 탐지 가능 => 기존 R-CNN에 비해 6배 빠른 성능
전체적인 구조
1) input이 들어오면 가로/ 세로를 동일한 Grid 영역으로 나눈다. 2) 각각의 Grid 영역은 어디에 사물이 존재하는지 Bounding Box와 Box에 대한 confidence score를 가진다. 3) 이와 동시에 (2)와 같이 classification 작업도 진행 4) 굵은 Box들만 남기고, 사물이 있을 확률이 낮은 것들은 지운다.(NMS 알고리즘 활용)
동작 과정
- 이미지를 4X4 Grid로 나누고, 각 Grid 셀마다 예측하는 Bounding Box는 2개, 전체 고려하는 class 개수는 20개 - 첫번째 예측된 Bounding Box는 파란색이며, pc = confidence score => confidence score = pr * IOU
# IOU
- 위에서 진행한 과정을 한 번 더 진행하여 두번째 Bounding Box에 대한 예측한 5가지 값에 대해 1차원 Tensor로 넣어준다. - 하늘색 박스의 마지막 부분엔 Grid 셀에 있는 object가 어떤 클래스인지 확률이 들어간다.
- 최종적으로 4X4X30의 output tensor가 나오게 된다. => 4X4 Grid 셀 각각 마다 5개의 값을 예측하는 2개의 Bounding Box(5*2 = 10개)와 20개의 클래스일 각각의 확률(20개)가 들어가 총 30개(10 + 20 = 30개)
Network Design
Training Stage
- IOU 값이 더 높은 노란색 Bounding Box만이 학습에 참여
YOLO Loss Function
B-box regression Loss
- 모든 Grid 셀에서 예측한 B개의 Bounding Box의 좌표(x, y, w, h)와 GT box 좌표의 오차를 구하는 공식
- S²: (s,s), 즉 feature map의 grid 수 - B: Anchor box의 수 - i 번째 cell 안에 2개의 detector 중에서 j 번째 detector가 responsible이면 1이고, not responsible이면 0
- Bounding Box의 중심 좌표 x i hat, y i hat과 ground truth의 중심 좌표 x i , y i의 오차 제곱을 나타내는 식
- width, height 도 마찬가지로 오차 제곱
- λ: 스케일링 적용
Confidence Loss
- 모든 Grid cell에서 예측한 B개의 클래스에 속할 확률값과 GT 값의 오차를 구하는 공식이다
- C i: 모델에서 구한 object일 확률 값과 IOU를 곱해 얻는다. - C i hat: GT confidence score로 1이다.
Classification Loss
- cell 내에 클래스가 존재할 확률을 구하는 공식
- pi(c): 해당 cell i 내부에 존재하는 object가 c class 일 확률이다.
Inference Stage
- 하나의 Grid를 확대해보면 총 크기 30의 output이 들어가 있다. - Inference하는 과정에서 class specific confidence score를 계
- Bounding Box의 개수만큼 32번 (16cell X 2개의 Bounding Box) 해준다. - 하나의 object마다 Bounding Box의 개수가 너무 많다. => NMS 적용
NMS(Nov-Maximum Suppression)
- Object Detection이 예측한 Bounding Box들 중에서 가장 정확한 한 Box만 선택 - 각 셀마다 confidence score가 가장 큰 Box를 고르고 선택한 Box와의 IOU가 임계값 보다 큰 Box는 모두 제거 - 하나의 Box만 남을때까지 진행