01. 인공지능과 방법론
- 인공지능: 일반적으로 인간 지능이 필요한 작업을 커퓨터 시스템이 수행하는 기술
- 강인공지능: 스스로 학습과 인식이 가능, 지능 또는 지성의 수준이 인간과 근사한 수준에 이른 경우
ex) 휴머노이드, 안드로이드
- 약인공지능: 인간이 해결할 수 있으나, 기존의 컴퓨터로 처리하기 힘든 작업을 처리하기 위한 일련의 알고리즘
1. 규칙 기반 AI: 미리 결정된 일련의 규칙 또는 알고리즘에 따라 문제를 해결하거나 작업을 수행
2. 머신러닝: 데이터를 이용해 모델을 학습하고, 이를 통해 예측이나 분류를 수행
3. 딥러닝: 정보를 처리하고 전송하는 방식을 시뮬레이션하도록 설계된 알고리즘인 인공 신경망을 사용, 머신러닝의 한 유형으로 대규모 데이터를 학습함으로써 성능 향상
머신러닝 시스템
- Machine Learning(기계 학습): 인공지능에 포함되는 영역 중 하나로, 데이터 기반으로 컴퓨터를 프로그래밍하는 연구 분야.
=> 기존 프로그래밍은 규칙과 데이터를 기반으로 결과값을 예측 / 머신러닝은 데이터와 결과값으로 규칙을 찾아냄

인공지능 > 머신러닝 > 딥러닝 > 신경망
- 인공 신경망(ANN, Artificial Neural Network): 인간의 뇌에 있는 신경 세포(뉴런)의 네트워크에서 영감을 통해 얻은 통계학적 학습 알고리즘
- 서로 연결된 노트의 집합으로 구성
- 여러 계층(layer)으로 이루어져 있다.
- 딥러닝(Deep Learning): 여러 신경망 계층과 대량의 데이터를 활용해 학습을 진행
- 입력층(Input layer): 학습하고자 하는 데이터를 전달 받는다.
- 은닉층(Hidden layer): 여러개의 은닉층을 지난다.
- 출력층(Output layer): 출력층에서 결과를 변환
알고리즘 기법
- 지도 학습(Supervised Learning): 훈련 데이터(Training data)와 레이블(Label)의 관계를 알고리즘으로 학습시키는 방법
=> Training data에 정답이 포함되어 있다.
- Training data는 Input data와 Output data로 구성
- Input data: 알고리즘이 풀고자 하는 문제
- Output data: 문제에 대한 정답
- 일반적으로 Input data의 속성은 벡터 형태로 구성
- 해당 벡터들이 어떤 의미를 내포하고 있는지 Labeling되어 있다.
- Labeling된 데이터를 스칼라 형태로 변환해 벡터와 스칼라 간의 관계를 분석하고 새로운 문제가 입력되었을때 정답을 유추하는 함수를 찾는다.
- Regression(회귀 분석): 둘 이상의 변수 간의 관계를 파악함으로써 독립 변수인 X로부터 연속형 종속 변수인 Y에 대한 모형의 적합도를 측정하는 방법
1. Simple Linear Regression Analysis(단순 선형 회귀 분석)
하나의 종속 변수와 하나의 독립 변수 사이의 관계를 분석하는 경우
2. Multi Linear Regression Analysis(다중 선형 회귀 분석)
하나의 종속 변수와 여러 개의 독립 변수 사이의 관계를 분석
- Classification(분류): 훈랸 데이터에서 지정된 레이블과의 관계를 분석해 새로운 데이터의 레이블을 스스로 판별하는 방법
=> 새로운 데이터를 대상으로 할당돼야 하는 카테고리 또는 범주를 스스로 판단
1. 이진분류(Binary Classification): 새로운 데이터를 대상으로 참인지 거짓인지 분류
2. 다중분류(Multiclass Classification): 세 개 이상의 카테고리로 나워 분류
softmax regression
- 비지도 학습(Unsupervised Learning): 훈련 데이터에 레이블을 포함시키지 않고 알고리즘이 스스로 독립 변수 간의 관계를 학습하는 방법
=> 레이블이 없이 입력 데이터를 대상으로 수행하므로 사전 학습을 필요로 하지 않는다.
=> 일련의 규칙인 f(x)를 통해 x에 대한 숨겨진 패턴이나 상관관계를 찾는 것을 목표
- Clustering(군집화): 입력 데이터를 기준으로 비슷한 데이터끼리 몇개의 군집으로 나누는 알고리즘
=> 입력 데이터의 특징을 고려해 데이터를 분류
=> 같은 군집으로 분류된 데이터끼리는 서로 비슷한 성질을 갖는다.
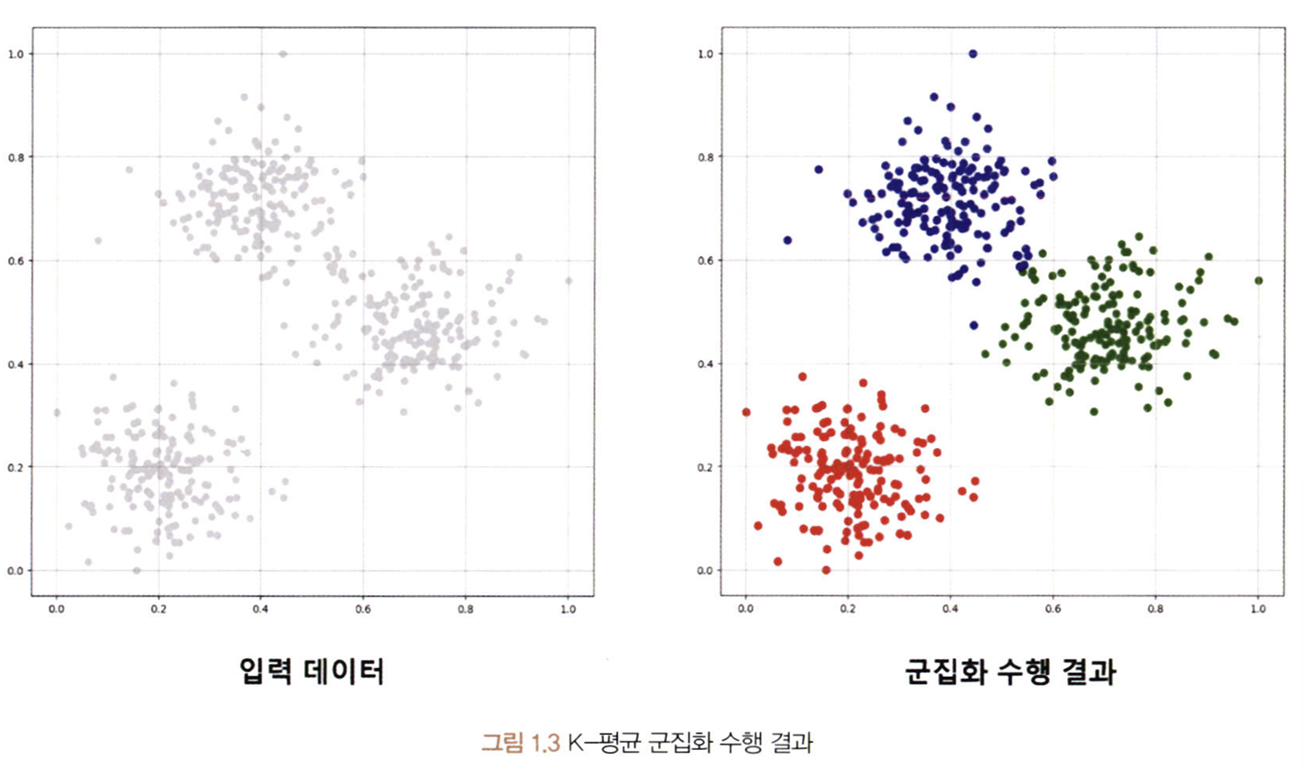
1. K-Means Clustering: 중심의 초깃값이 무작위로 정해지며, K의 개수만큼 군집을 이룬다.
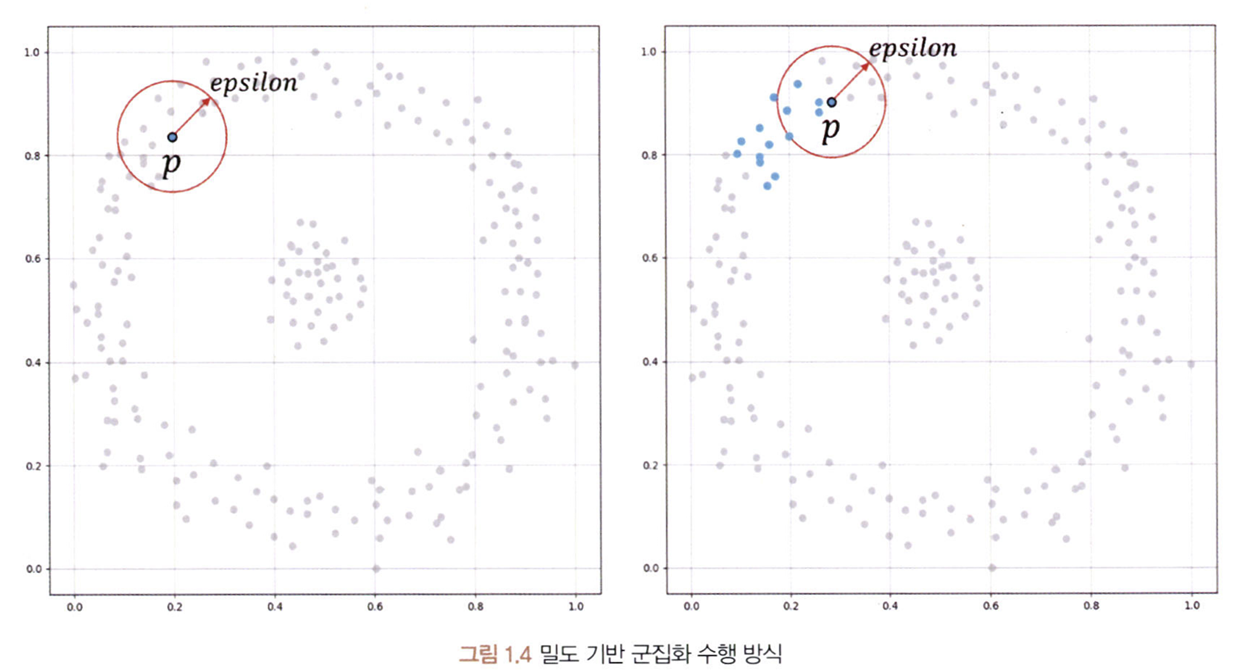
2. DBSCAN: 특정 공간 내에 데이터가 많이 몰려 있는 부분을 대상으로 군집화하는 알고리즘
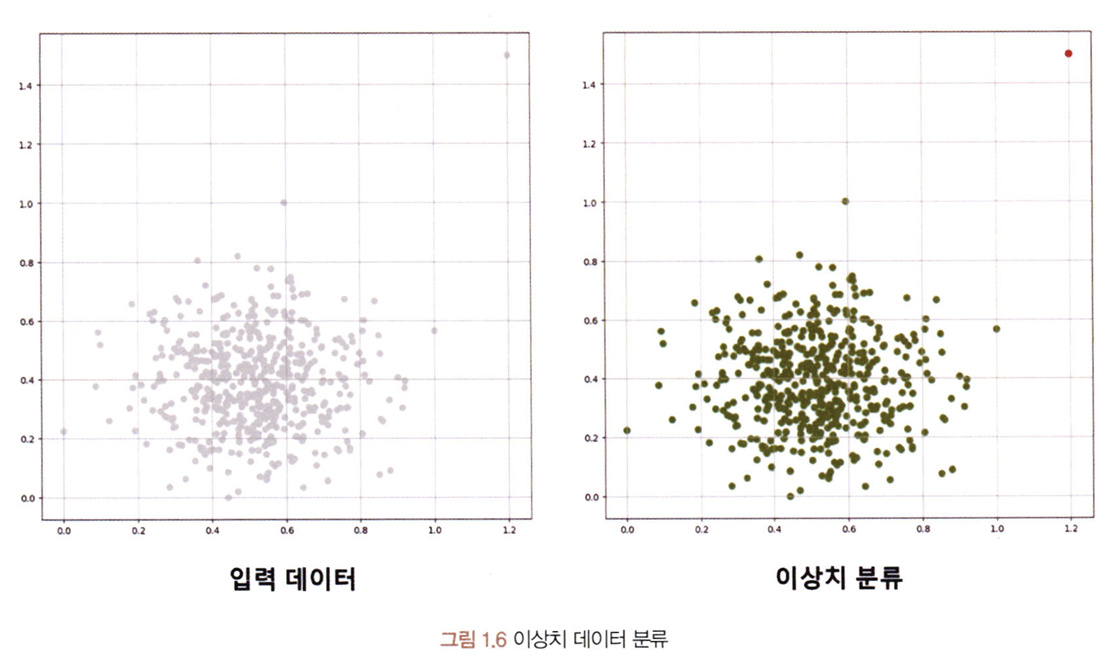
- Outlier Dtection, Anomaly Detection(이상치 탐지): 밀도가 높은 데이터 분포에서 멀리 떨어져 있는 샘플을 찾는 것
- Dimensionality Reduction(차원 축소): 고차원 데이터의 차원을 축소해 저차원의 새로운 데이터로 변환하는 것
1. Feature Selection(특징 선택): 모델의 성능 향상에 유용한 특징 변수들을 불필요한 변수들을 제거하는 것을 의미
2. Feature Extraction(특징 추출): 여러 특징을 하나로 압축해 새로운 특징을 만들어 내는 것을 의미
PCA, SVD...
- 준지도 학습(Semi-supervised Learning): 레이블을 사용하는 지도 학습과 레이블을 사용하지 않는 비지도 학습의 중간에 있는 학습 방법
=> 레이블이 포함된 데이터와 포함되지 않은 데이터를 함께 학습에 활용

Auto Encoder, GAN과 같은 생성 모델등에 활용
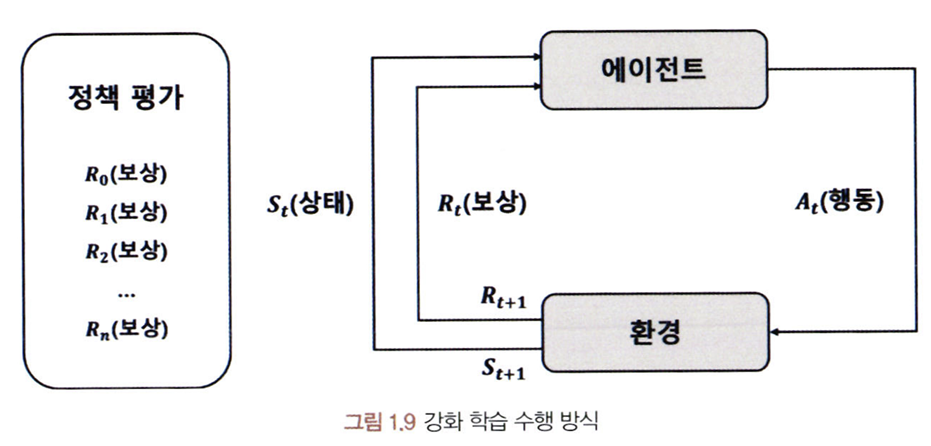
- 강화학습(Reinforcement Learning):어떤 행동을 수행했을 때 보상이 있다면 보상받았던 행동의 발생 빈도가 높아진다.
- Environment: 학습을 진행하는 공간 또는 배경
- Agent: 환경과 상호작용하는 프로그램
- State: 환경에서 에이전트의 상황
- Action: 주어진 환경의 상태에서 에이전트가 취하는 행동
- Reward: 현재 환경의 상태에서 에이전트가 어떠한 행동을 취했을 때 제공되는 것
- Policy: 에이전트가 보상을 최대화하기 위해 행동하는 알고리즘
- 마르코프 결정 과정(Markov Decision Process, MDP): 이산 시간 확률 제어 과정으로 시간에 따른 시스템의 상태 변화
=> 순차적으로 행동을 결정해야 하는 문제를 풀기 위해 의사결정 과정을 모델링 하는것
# 마르코프 속성: 과거 상태와 현재 상태가 주어졌을 때, 미래 상태는 오직 현재 상태에 의해 결정된다는 것.
=> 과거 상태와는 별개로 현재 상태에 의해서만 결정된다는 의미
- 가치 함수(Value Function): 어떤 상태에서 정책에 따라 행동할 때 얻게 되는 기대 보상을 의미
=> 상태와 행동에 따라 최종적으로 어떤 보상을 제공해 줄지에 대한 예측 함수
- 상태-행동 가치 함수(State-Action Value Function): 어떤 상태에서 행동한 다음, 정책에 따라 행동할 때 얻게 되는 기대 보상
강화학습은 시행착오를 통해 보상을 최대로 할 수 있는 정책을 찾는 방법으로 학습이 진행