[Review]MOTR: End-to-End Multiple-Object Tracking with Transformer
Donghun Kang2025. 2. 23. 17:07
0. Abstract
- 객체의 시간적 모델링(Temporal modeling)은 다중 객체 추적(Multiple-Object Tracking, MOT)에서 중요한 도전 과제이다. - 기존 방법들은 탐지된 객체를 모션 기반 및 외형(appearance) 기반 유사성(heuristics)을 활용하여 연관(association)하는 방식을 사용 - 그러나, 이러한 연관 과정이 후처리(post-processing)로 수행되기 때문에, 비디오 시퀀스에서 시간적 변화를 End-to-End 방식으로 활용하는 것이 불가능하다.
<MOTR> - 이는 기존 DETR (DEtection TRansformer)모델을 확장한 방식이며, "Track Query"개념을 도입하여 전체 비디오에서 추적된 객체를 모델링한다. - Track Query는 프레임별로 전이(transfer)되고 업데이트(update)되며, 이를 통해 시간에 따른 반복적인 예측(iterative prediction)이 가능
- 우리는 "Tracklet-Aware Label Assignment (TALA)" 기법을 제안하여 Track Query와 새롭게 등장하는(Newborn) 객체 Query를 학습할 수 있도록 한다. - 또한, Temporal Aggregation Network (TAN) 및 Collective Average Loss (CAL) 을 도입하여 시간적 관계 모델링(Temporal Relation Modeling)을 더욱 향상
- 기존 DETR을 확장한 MOTR 모델을 제안. - "Track Query"를 도입하여 객체의 연속적인 추적을 Transformer 기반으로 수행 - TALA, TAN, CAL 기법을 사용
1. Introduction
- 다중 객체 추적(Multiple-Object Tracking, MOT)은 연속된 이미지 시퀀스에서 객체의 궤적(trajectory)을 예측하는 작업 - 기존 MOT 방법들은 시간적 연관(temporal association) 과정을 "외형(appearance)"과 "운동(motion)"의 두 가지 요소로 분리하는 방식을 사용 1. 외형(appearance) 정보는 Re-ID (Re-identification) 유사도를 이용하여 객체를 식별 2. 운동(motion) 정보는 IoU (Intersection over Union) 또는 칼만 필터(Kalman Filtering)와 같은 기법을 통해 모델링 => 기존 방법들은 프레임 간 객체 연관을 위해 후처리 단계(Post-processing)를 필요로 하며, 이 과정에서 시간적 정보 흐름(Temporal Information Flow)에 병목 현상(bottleneck)이 발생
- DETR은 객체 탐지를 집합 예측(Set Prediction) 문제로 정의 하며, 기존의 NMS(Non-Maximum Suppression)와 같은 후처리 과정을 제거 DETR
1. DETR에서는 객체를 표현하는 Object Query를 Transformer 디코더에 입력 2. 이를 이미지 특징과 상호작용하여 업데이트 3. Bipartite Matching을 통해 탐지된 객체와 Ground-Truth를 직접 1:1 매칭하는 방식을 사용 => 이를 통해 추가적인 후처리 없이 객체 탐지가 가능
다중 객체 추적(MOT)은 단순한 객체 탐지 문제가 아닌 시퀀스 예측 문제(Sequence Prediction Problem) 그렇다면, DETR을 확장하여 "End-to-End 다중 객체 추적"을 수행할 방법은 무엇일까?
- 우리는 MOT를 "집합 시퀀스 예측(Set of Sequence Prediction)" 문제로 간주 - MOT는 여러 개의 객체 시퀀스를 추적해야 하므로, 각 객체의 궤적을 하나의 시퀀스로 볼 수 있다. - DETR의 "Object Query"를 "Track Query"로 확장하여, 프레임 간 객체 시퀀스를 예측 - Track Query는 객체의 은닉 상태(Hidden State) 역할을 하며, Transformer 디코더에서 계속 업데이트되면서 객체 궤적을 예측하는 방식
이를 위해, 2가지 문제를 해결해야 한다. 1. 하나의 객체를 하나의 Track Query로 지속적으로 추적할 방법 ==> Tracklet-Aware Label Assignment (TALA) : 동일한 객체 ID를 가진 바운딩 박스 시퀀스를 하나의 Track Query로 학습하도록 유도하는 기법
2. 새롭게 등장하는 객체(Newborn Objects)와 사라지는 객체(Terminated Objects)를 처리할 방법 ==> Variable-Length Track Query Set
새로운 객체는 Track Query Set에 동적으로 추가되며,
사라진 객체는 Track Query Set에서 제거된다.
이를 Entrance and Exit Mechanism이라고 부른다.
이를 통해, MOTR은 추적 과정에서 별도의 Explicit Track Association이 필요하지 않다.
- 추가적으로 시간적 모델링을 더욱 강화하기 위해 다음 두가지 기법을 제안 1. Collective Average Loss (CAL) : 비디오 클립 전체를 학습 샘플로 사용 / 모델이 보다긴 시간 범위(Long-range Temporal Modeling)를 학습 2. Temporal Aggregation Network (TAN) : Track Query가 이전 상태에서 축적된 시간적 정보를 활용할 수 있도록 Transformer 기반 Key-Query Attention 메커니즘을 도입.
=> DETR을 기반으로 소수의 레이블 할당(Label Assignment) 메커니즘만 추가하여 쉽게 구현 가능 => 추가적인 후처리 과정 없이 완전한 End-to-End MOT 프레임워크를 제공 (기존 Transformer 기반 MOT 모델(TrackFormer)에서는 여전히 Track NMS 또는 IoU 매칭을 사용) MOTR은 이러한 후처리를 전혀 사용하지 않는다.
- 후처리 없이 Frame 간 객체 sequence를 직접 예측하는 MOTR 제안
2. Related Work
Transformer-based Architectures
- Transformer는 원래 기계 번역(machine translation)을 위해 도입된 모델로, 전체 입력 시퀀스로부터 정보를 집계(aggregate)하는 구조를 가진다. - 이 모델의 핵심은 Self-Attention 및 Cross-Attention 기법을 활용하여 입력 데이터의 관계를 학습하는 것 EX) DETR, Deformable DETR, ViT, Swin Transformer, VisTR ....
Multi-Object Tracking(MOT)
- 기존 MOT 방법들은 주로 Tracking-by-Detection 방식 1. 먼저 객체 탐지(Object Detection) 를 수행 2. 연속된 프레임 간 탐지된 객체들을 연결(Association)하여 궤적(Trajectory)을 형성하는 방식
<SORT> - 칼만 필터(Kalman Filter)와 헝가리 알고리즘(Hungarian Algorithm)을 결합하여 객체 연관 수행. - 객체 간 IoU(Intersection-over-Union) 기반 연관 매칭을 수행하는 단순하고 빠른 방법.
<Deep SORT, Tracktor> - 객체의 외형(appearance) 정보를 활용하여 Re-ID(Re-identification) 유사도를 기반으로 추적 성능을 개선.
<Track-RCNN, JDE, FairMOT> - 객체 탐지(Detection)와 Re-ID를 하나의 네트워크에서 학습하는 방식. - 탐지 성능과 추적 성능을 동시에 최적화하여 연산 효율성 증가.
<TransMOT> - Transformer를 기반으로 공간-시간적 그래프(Spatial-Temporal Graph)를 활용한 연관 방법을 제안.
Iterative Sequence Prediction
- Transformer 기반 모델은 Seq-2-Seq 기법을 통해 반복적인 시퀀스 예측을 수행 - 이러한 반복적 예측 기법을 MOT(다중 객체 추적) 문제에 적용할 경우 1. 객체 궤적을 하나의 시퀀스로 모델링 가능 2. Track Query를 은닉 상태(Hidden State)로 활용하여 프레임별로 갱신(Update)하는 방식으로 확장 가능.
- 기존 DETR 모델의 Object Query를 Track Query로 확장 - 객체의 시간적 상태를 지속적으로 업데이트하며 추적을 수행하는 방법을 제안
3. Method
3.1 Query in Object Detection
- DETR은 고정된 길이(Fixed-length)의 객체 쿼리(Object Query) 집합을 사용하여 객체를 탐지 - 본 논문에서는 DETR의 "Object Query"를 "Detect Query"라고 명명하여, MOT(다중 객체 추적)에서 사용되는 "Track Query"와 구별
3.2 Detect Query and Track Query
- DETR을 객체 탐지(Object Detection)에서 다중 객체 추적(MOT) 으로 확장하는 과정에서 두 가지 문제가 발생 1. 하나의 객체를 하나의 Track Query로 지속적으로 추적하는 방법 2.새롭게 등장하는 객체(Newborn Objects)와 사라지는 객체(Terminated Objects)를 처리하는 방법 => 기존의 Detect Query를 확장하여 Track Query를 도입함으로써 문제를 해결
Detect Query
- 새로운 객체 (Newborn Objects)를 탐지하는 역할
- DETR에서의 기존 Object Query와 유사한 개념
Track Query
- 이미 존재하는 객체를 Frame 별로 Tracking하는 역할
- Track Query는 이전 Frame에서의 객체 상태를 기반으로 update
- Track Query의 길이는 동적으로 변하며, 새로운 객체가 등장하면 길이가 증가하고, 객체가 사라지면 감소
2. Frame Update(T2~Tn) - 이전 프레임에서 생성된 Track Query를 Transformer 디코더에 입력. - Track Query는 이미 추적 중인 객체의 상태를 업데이트하는 역할. - 새로운 객체가 등장하면 Detect Query가 이를 탐지하여 새로운 Track Query를 생성. - 반대로, 객체가 사라지면 해당 Track Query는 삭제됨.
- Track Query는 "객체의 은닉 상태(Hidden State)" 역할을 수행 - 프레임별로 지속적으로 업데이트되면서 시간적 일관성을 유지할 수 있도록 설계됨. - 이러한 방식은 기존의 Tracking-by-Detection 방식과 달리, 명시적인 객체 연관(Association) 과정이 필요 없음.
3.3 Tracklet-Aware Label Assignment (TALA)
- DETR에서 객체 탐지(Object Detection)는 객체 쿼리(Object Query)와 Ground-Truth 간의 Bipartite Matching을 통해 1:1로 매칭되는 방식으로 학습
- MOTR에서는 Detect Query와 Track Query가 동시에 존재하며, 이를 효과적으로 학습하기 위해 새로운 레이블 할당(Label Assignment) 기법인 Tracklet-Aware Label Assignment (TALA)를 제안
기존 DETR 방식
- 각 프레임에서 새로운 객체를 탐지하고 개별적으로 매칭
- 기존 객체의 추적(Tracking) 정보가 유지되지 않음.
[개선점]
- Detect Query는 새로운 객체(Newborn Objects)만 탐지하도록 제한
- Track Query는 이미 존재하는 객체를 추적하도록 학습
- Track Query와 동일한 ID의 객체가 지속적으로 매칭되도록 보장해야 함.
Tracklet-Aware Label Assignment (TALA)
1. Detect Query를 위한 레이블 할당 (Newborn-Only Matching) - Detect Query는 오직 새로운 객체(Newborn Objects)에만 할당되어야 한다. - 따라서, 기존 DETR에서 사용되던 Bipartite Matching을 새롭게 등장한 객체에 한해서만 수행. - 즉, Detect Query는 이미 존재하는 객체를 탐지하지 않도록 제한. 기존 DETR의 Bipartite Matching을 수정 2. Track Query를 위한 레이블 할당 (Target-Consistent Assignment) - Track Query는 이전 프레임에서 할당된 객체 ID를 그대로 유지해야 한다. - 따라서, 이전 프레임에서 매칭된 객체 ID를 현재 프레임에서도 유지하는 방식으로 레이블을 할당. - Track Query는 기존 프레임의 트랙 정보를 기반으로 지속적인 매칭이 이루어지도록 보장. Track Query는 이전 프레임에서의 매칭 결과를 그대로 유지
[TALA의 효과] Detect Query와 Track Query의 역할을 명확히 분리 - Detect Query: 새로운 객체 탐지. - Track Query: 기존 객체 추적.
1. 각 프레임에서 객체의 ID가 유지될 수 있도록 보장. 2. Detect Query와 Track Query의 역할을 분리하여 추적 성능을 향상. 3. Transformer의 Self-Attention을 활용하여 중복 탐지를 억제.
3.4 MOTR Architecture
- MOTR의 전체적인 아키텍처는 Transformer 기반의 End-to-End 다중 객체 추적 프레임워크로 구성
MOTR Architecture
MOTR 전체 Architecture
1. Video Input
비디오 프레임이 CNN 백본(예: ResNet-50) 및 Transformer 인코더(Deformable DETR)로 입력됨.
이를 통해 각 프레임의 이미지 특징(Image Feature)을 추출.
2. Detect Query와 Track Query의 결합
첫 번째 프레임에서는 Detect Query만 존재하며, 모든 객체를 탐지.
이후 프레임부터는 이전 프레임에서 생성된 Track Query와 Detect Query를 함께 Transformer 디코더에 입력.
3. Transformer 디코더 (Deformable DETR Decoder)
Detect Query와 Track Query는 Transformer 디코더에서 이미지 특징과 상호작용하여 업데이트됨.
Detect Query는 새로운 객체(Newborn Objects)를 탐지하는 역할.
Track Query는 기존 객체의 위치를 지속적으로 추적하는 역할.
4. 출력 및 Query Interaction Module (QIM)
Transformer 디코더의 출력을 바탕으로, 객체의 위치(Bounding Box) 및 ID를 예측.
Query Interaction Module (QIM) 에 의해, Track Query가 다음 프레임으로 전달됨.
QIM은 새롭게 등장한 객체를 Track Query Set에 추가하고, 사라진 객체를 제거하는 역할 수행.
3.5 Query Interaction Module(QIM)
- Query Interaction Module (QIM)의 2가지 주요 기능 1. 객체 입출구 관리 (Object Entrance and Exit Mechanism) 2. 시간적 정보 통합 (Temporal Aggregation Network, TAN)
Object Entrance and Exit Mechanism
- Track Query Set의 길이를 동적으로 조정하여 새로운 객체(Newborn Object)의 등장과 기존 객체(Terminated Object)의 소멸을 처리
1. 새로운 객체(Newborn Object)의 추가 - 새로운 객체가 등장하면, Detect Query가 이를 탐지하고 해당 객체에 대해 새로운 Track Query를 생성함. - 이 과정은 프레임별로 Detect Query와 Ground-Truth를 비교하여 이루어짐.
2. 기존 객체(Terminated Object)의 삭제 - 특정 객체가 Ground-Truth에서 사라졌거나, 모델이 더 이상 해당 객체를 신뢰하지 않을 경우, 해당 Track Query를 제거함. - 이를 위해 객체의 신뢰도(Confidence Score) 를 활용하여 Exit Threshold 이하일 경우 객체를 삭제.
3. 훈련(Training) 및 추론(Inference)에서의 입출구 관리 차이점 [훈련 시(Training)] - Ground-Truth 정보를 이용하여, 객체가 사라졌는지 확인하고 Track Query를 삭제. - 만약 예측된 바운딩 박스가 Ground-Truth와 IoU가 0.5 이하라면 해당 Track Query를 제거.
[추론 시(Inference)] - 객체의 신뢰도(Confidence Score)를 기반으로 Track Query를 유지 또는 삭제. - 신뢰도가 일정 임계값(Exit Threshold) τ_ex 이하로 M 프레임 동안 유지되면 Track Query를 삭제.
=> Track Query Set이 불필요하게 커지는 것을 방지하고, MOTR이 보다 동적으로 객체를 추적할 수 있도록 함
Temporal Aggregation Network (TAN)
- MOTR에서 시간적 정보(Temporal Information)를 효과적으로 활용하기 위해 Temporal Aggregation Network (TAN) 을 QIM에 추가
1. TAN의 역할 - 이전 프레임에서 사용된 Track Query를 현재 프레임에 전달하여,시간적 일관성(Temporal Consistency) 을 유지.- - 객체의 이동 궤적을 보다 부드럽게 예측 가능.이를 위해 Transformer의 Key-Query Attention 기법을 활용.
2. TAN의 동작 과정 [Track Query 업데이트] - 이전 프레임의 Track Query와 현재 프레임에서 새롭게 생성된 Detect Query를 결합. - 이를 Transformer의 Self-Attention을 활용하여 업데이트.
[Query Interaction 수행] - Track Query를 Multi-Head Attention(MHA)의 Key & Query로 사용. - 이전 프레임의 정보를 반영하여 Track Query를 보정.
[최종 Track Query 생성] - TAN을 통과한 Track Query는 현재 프레임에서의 최종 예측에 사용되며, 이후 프레임으로 전달.
=> Track Query는 각 프레임에서 독립적으로 갱신되지 않고, 시간적 흐름을 반영한 채로 지속적으로 업데이트
3.6 Collective Average Loss (CAL)
기존 학습 방식의 문제점
- 기존 MOT 학습 방식에서는 2개 프레임 간의 관계만 학습하는 것이 일반적 1. 프레임 간 객체의 단기적 이동만 반영할 수 있으며, 2. 장기적인 객체의 궤적을 학습하는 것이 어려움. => MOT 모델은 짧은 구간에서는 잘 동작하지만, 긴 시퀀스에서는 ID 스위치(Identity Switch)가 빈번하게 발생
Collective Average Loss (CAL)
- CAL은 이러한 문제를 해결하기 위해, 비디오 전체를 학습 샘플로 활용하는 새로운 손실 함수
[특징] 1. 비디오 클립 전체를 학습 데이터로 사용 - 기존 방식처럼 단순히 연속된 두 개 프레임을 학습하는 것이 아니라,하나의 비디오 클립(여러 프레임) 전체를 학습하는 방식. 2. 시간적 일관성을 고려한 Loss 계산 - 각 프레임에서 Track Query가 지속적으로 유지되는 것을 학습. - 전체 비디오 내에서 동일 객체가 같은 ID를 유지하도록 학습.
[수식] CAL 수식
- CAL은 전체 비디오 클립을 학습 데이터로 사용하기 위해 비디오 전체에 대한 손실을 계산 - 기존 DETR과 동일하게 Focal Loss, L1 Loss, GIoU Loss를 사용. - 다만, 단일 프레임이 아니라 비디오 전체에서의 평균 손실을 계산 함으로써, 객체의 장기적인 이동을 학습하고, ID 유지가 더욱 원활하도록 유도.
3.7 Discussion
TransTrack
- TransTrack은 MOT를 "짧은 트랙릿(Short Tracklets)"의 조합으로 모델링 - 즉, 두 개의 연속된 프레임에서 객체를 탐지하고, 이를 IoU 기반의 매칭을 통해 연결하는 방식을 사용 - Tracking-by-Detection 방식과 유사하며, 객체 연관(Association)이 후처리로 수행
<MOTR과의 차이점> - TransTrack은 IoU 기반의 트랙릿 연결이 필요 - MOTR은 Track Query를 통해 객체의 연속적인 상태를 직접 모델링 - 즉, MOTR은 IoU 매칭 없이 End-to-End 방식으로 객체를 추적.
TrackFormer
- TrackFormer는 Track Query 개념을 도입하여, 객체의 지속적인 추적을 수행 - 하지만, TrackFormer는 인접한 두 프레임만 학습하는 방식이므로,장기적인 시간 정보를 학습하기 어려운 구조 - 이를 보완하기 위해, TrackFormer는 Track NMS 및 Re-ID 특성(Feature)을 추가적으로 사용
<MOTR과의 차이점> - TrackFormer는 두 프레임 간 학습을 수행하기 때문에, 긴 시퀀스에서 ID 유지가 어려움. - 반면, MOTR은 전체 비디오 클립을 학습하며(CAL 적용), 보다 강력한 시간적 모델링이 가능. - MOTR은 Track NMS 및 Re-ID 같은 추가적인 후처리를 필요로 하지 않음.
한계
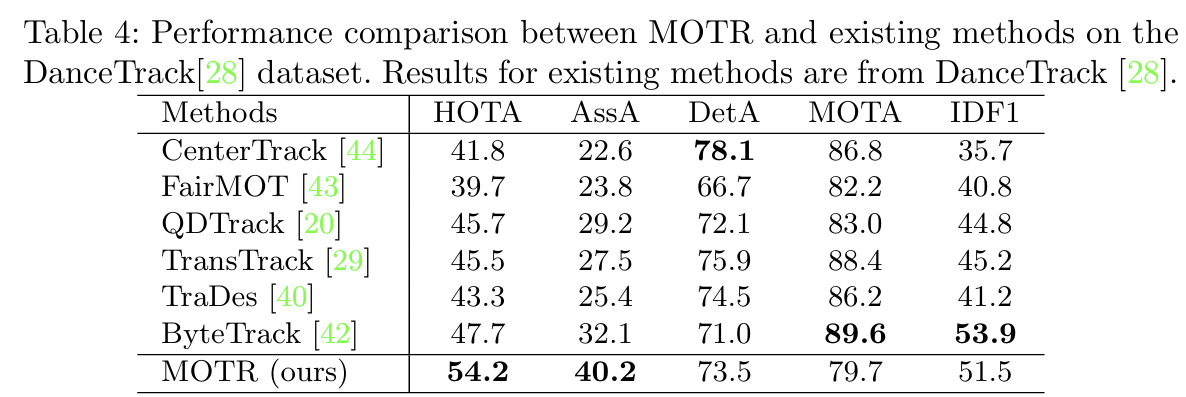
1. 탐지 성능(MOTA)이 ByteTrack보다 낮음 => DETR의 Detect Query와 Track Query를 보다 효과적으로 조합할 필요가 있음.
2. 프레임 간 Track Query 전달 방식이 단순함 => VisTR의 병렬 디코딩 기법을 MOTR에 적용하는 것을 고려.
3. 학습 속도가 상대적으로 느림 => Deformable DETR의 Sparse Attention 기법을 추가적으로 활용하면 속도 개선 가능.
- MOTR은 DETR을 확장하여 Detect Query와 Track Query를 도입 - Tracklet-Aware Label Assignment (TALA)와 Collective Average Loss (CAL) 을 활용하여 객체의 지속적인 ID 유지 및 장기적인 시간 정보 학습을 강화 - Query Interaction Module (QIM)과 Temporal Aggregation Network (TAN) 을 통해 새로운 객체 탐지 및 기존 객체 관리, 프레임 간 관계 학습을 최적화
4. Experiments
4.1 Datasets and Metrics
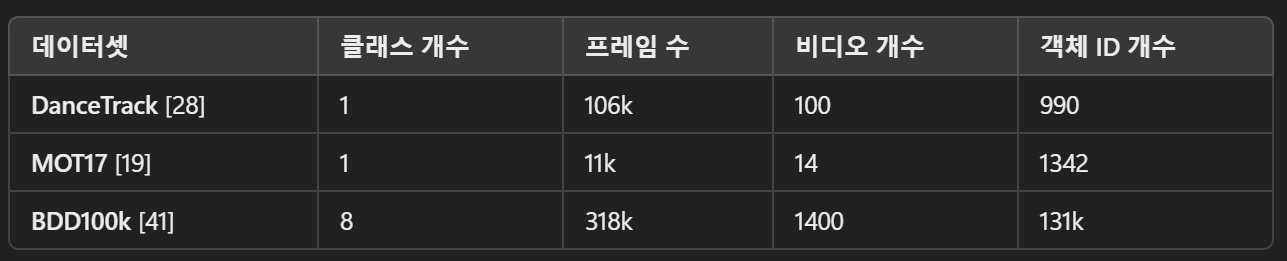
Datasets
Metrics
HOTA (Higher Order Tracking Accuracy)
- 객체 탐지(Detection)와 객체 연관(Association) 성능을 종합적으로 평가하는 지표
MOTA (Multiple-Object Tracking Accuracy)
- 추적된 객체 수, FP(False Positives), FN(False Negatives), ID 스위치를 반영한 전통적인 평가 지표
- 높은 MOTA는 더 정확한 추적을 의미하지만, 객체 연관(Association) 성능은 반영하지 않음.