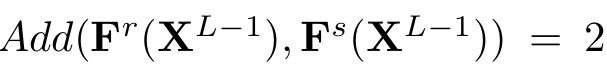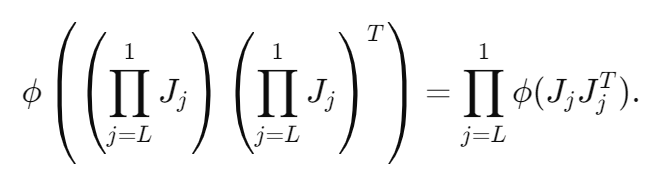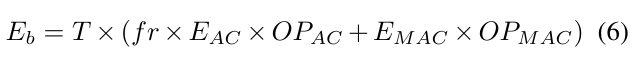- SNN은 뇌에서 영감을 받은 에너지 효율적인 모델로, 공간-시간적(spatiotemporal) 정보를 활용하여 연산을 수행 - 객체 탐지(Object Detection)와 같은 회귀(Regression) 문제에 직접 학습된 SNN을 적용하는 것은 여전히 과제
- " EMS-YOLO" 라는 새로운 직접 학습 SNN 프레임워크를 제안 - ANN-SNN 변환 없이 surrogate gradient를 활용하여 직접 학습되는 최초의 SNN 기반 객체 탐지 모델
<장점> 1. 깊은 네트워크 학습 가능 (Gradient Vanishing/Exploding 문제 해결) 2. 낮은 전력 소비 유지 (Non-Spike 연산 최소화)
- 실험 결과, EMS-YOLO는 기존 ANN-SNN 변환 모델(최소 500개의 타임 스텝 필요)보다 훨씬 적은 4개의 타임 스텝만으로 더 나은 성능을 달성 - COCO 및 Gen1 데이터셋을 활용한 실험에서, 동일한 구조의 ANN과 유사한 성능을 내면서도 전력 소비를 5.83배 줄이는 데 성공
- EMS-YOLO는 최초의 직접 학습(Direct Training) SNN 객체 탐지 모델 - EMS-ResNet 설계를 통해깊은 네트워크 학습 가능, 에너지 효율적 연산 가능 - COCO 및 Gen1 데이터셋에서 ANN과 유사한 성능을 내면서 5.83배 적은 전력 소비
1. Introduction
- 대부분의 기존 객체 탐지 프레임워크(예:YOLO 시리즈, RCNN 시리즈)는 인공 신경망(ANNs)을 기반으로 한다. - 이러한 ANN 기반 탐지 모델들은 높은 성능을 제공하지만, 연산 복잡도가 크고, 에너지 소비가 높다는 단점
- SNN은 뇌에서 영감을 받은 3세대 신경망으로, 기존 ANN과 달리 연속적인 활성화 값을 사용하지 않고, 이진 신호(Spike)로 정보를 전달 - SNN은 데이터 전송 및 저장 오버헤드를 줄이며, 에너지 효율적인 신경망을 구현
<SNN의 주요 장점> 1. 이진 신호(Spike) 사용 → 데이터 전송 및 저장 비용 감소 2. 이벤트 기반(Event-Driven) 연산 → 불필요한 연산 제거 가능 3. 뉴로모픽 하드웨어(Neuromorphic Hardware)에서 높은 에너지 효율성 제공
ANN-SNN 변환
- 기존의 SNN 기반 객체 탐지 모델은 대부분 ANN-SNN 변환 방식을 사용
<ANN-SNN 변환 방식의 문제점> 1. 매우 긴 타임 스텝(Time Steps)이 필요 Spiking-YOLO (기존 연구): ANN 성능을 맞추려면 최소 3500개의 타임 스텝 필요 Spike Calibration (기존 연구): 수백 개의 타임 스텝 필요
2. ANN 성능에 의존함 ANN-SNN 변환 방식은 ANN의 출력을 SNN의 발화율(Firing Rate)로 변환하는 방식이므로, ANN의 성능에 의존적.
3. 이벤트 기반(Event-Based) 데이터에 적합하지 않음 기존 방법들은 대부분 정적 이미지(Static Image)만을 처리하도록 설계됨. 이벤트 카메라(DVS)에서 수집한 시간에 따라 변화하는 데이터 처리에 부적합.
Direct Training SNN (Surrogate Gradient 이용)
- Surrogate Gradient를 이용한 직접 학습(Direct Training) 방법을 사용 - SEW-ResNet, MS-ResNet 등의 연구를 통해 SNN이 100층 이상의 깊이로 학습 가능하다는 것이 확인됨. - 이러한 연구들은 대부분 분류(Classification) 문제에 초점을 맞추고 있음. - 객체 탐지(Object Detection)와 같은 회귀(Regression) 문제를 해결하는 직접 학습 SNN 연구는 거의 존재 X
EMS-YOLO
- ANN-SNN 변환 없이 직접 학습된 최초의 깊은 SNN 객체 탐지 모델
<Distribution> 1. EMS-YOLO: 직접 학습된 최초의 SNN 객체 탐지 모델 ANN-SNN 변환 없이 서러게이트 그래디언트를 활용한 직접 학습(Direct Training) SNN 모델을 구현.
2. EMS-ResNet: 완전한 스파이크 기반 잔차 블록(Residual Block) 기존 SEW-ResNet, MS-ResNet의 한계를 해결하고, 완전한 스파이크 연산(Full-Spike Computing)을 지원. Non-Spike연산을 제거하여 전력 소비 감소. 깊은 네트워크 학습 가능 → Gradient Vanishing/Exploding 문제 해결.
3. 효율적인 성능 및 에너지 절약 COCO 및 Gen1 데이터셋에서 ANN과 유사한 성능을 유지하면서도 전력 소비를 5.83배 절감. 기존 ANN-SNN 변환 방법보다 훨씬 적은 4개의 타임 스텝만으로 더 높은 성능을 달성.
- ANN 기반 방법들은 높은 연산 비용과 전력 소비 문제 - 기존 ANN-SNN 변환 방식은 성능 저하 및 긴 타임 스텝이 필요하다는 문제 - EMS-YOLO는 직접 학습된 SNN 객체 탐지 모델, ANN-SNN 변환 없이 깊은 학습이 가능, 전력 소비가 적다 - EMS-ResNet을 활용하여 Non-Spike 연산을 제거하고, 더 깊고 효율적인 SNN 구조를 설계
2. Related Work
2.1. Deep Spiking Neural Networks
Deep SNN의 학습 전략은 크게 2가지로 나뉜다.
ANN-SNN Conversion
- ANN-SNN 변환의 본질은 SNN의 평균 발화율(Firing Rate)을 ANN의 ReLU 활성화 값과 동일하게 만드는 것 - 즉, ANN에서 훈련된 모델을 SNN으로 변환하여 활용하는 방법
<한계점> 1. ANN에 의존적 ANN 모델의 성능이 낮으면 SNN 성능도 낮아짐.
2. 긴 타임 스텝 필요 ANN-SNN 변환 모델들은 일반적으로 매우 많은 타임 스텝을 필요 예) Spiking-YOLO는 ANN 성능을 맞추기 위해 최소 3500개의 타임 스텝 필요.
3. 이벤트 기반 데이터와 호환되지 않음 ANN-SNN 변환 방식은 정적 이미지 처리에 최적화 그러나, DVS(Event-based) 카메라 데이터 처리에는 부적합. 이벤트 데이터를 활용하는 뉴로모픽 하드웨어와의 결합이 어려움.
Direct Training SNNs
- 최근 연구에서는 Surrogate Gradient기법을 활용하여, SNN을 ANN처럼 역전파(Backpropagation) 방식으로 훈련 - ANN-SNN 변환 없이 직접 SNN을 훈련
<장점> 1. 짧은 타임 스텝에서도 높은 성능 가능 ANN-SNN 변환 방식과 달리 수십~수백 개의 타임 스텝이 필요하지 않음. 예) 기존 연구에서 50개 이하의 타임 스텝으로도 깊은 SNN 훈련 가능.
2. 이벤트 기반 데이터와 호환 가능 이벤트 데이터를 활용하는 뉴로모픽 하드웨어에서 더 적합한 방식.
<한계점> 1. 대부분 분류(Classification) 문제에만 적용 기존 연구에서는 분류(Classification) 문제에만 집중. 대표적인 예: TDBN (Threshold-Dependent Batch Normalization) 기법 → 50층 이상의 SNN 학습 가능. MS-ResNet, SEW-ResNet → 100층 이상의 깊은 SNN 학습 가능. 하지만, 객체 탐지(Object Detection)와 같은 회귀(Regression) 문제에는 거의 적용되지 않음.
2. 객체 탐지에 대한 연구 부족 현재까지 SNN을 직접 학습하여 객체 탐지 모델을 훈련한 연구는 없음. 본 논문은 객체 탐지 문제를 직접 학습된 SNN으로 해결하는 최초의 연구임.
2.2 Energy-Efficient Object Detection
객체 탐지에서 Visual Sensors는 크게 두 가지로 나뉜다.
프레임 기반(Frame-Based) 카메라
이벤트 기반(Event-Based) 카메라
기존의 객체 탐지 모델들은 프레임 기반 ANN(Artificial Neural Network) 탐지 모델을 주로 사용하며, 이러한 모델은 크게 두 가지 방식으로 나뉜다.
Two-Stage 방식 (예: RCNN 계열)
One-Stage 방식 (예: YOLO 계열, SSD, Transformer 기반 탐지 모델)
이러한 ANN 기반 탐지 모델들은 높은 성능을 제공하는 대가로 높은 연산량과 에너지 소비를 초래
SNN base Object Detection
ANN-to-SNN Conversion
- 기존 연구들은 Static Images탐지에만 초점을 맞추고 있어, 이벤트 카메라 데이터와 호환성이 떨어짐 => 많은 Time step이 필요하다.
Hybrid Architecture
- 일부 연구에서는 SNN 백본(Backbone) + ANN 탐지 헤드(Detection Head)를 결합하는 방식 시도. - 하지만, ANN 탐지 헤드가 추가되면서 전체적인 연산량과 전력 소비가 증가.
EMS-YOLO
- 본 논문은 완전한 SNN 기반 탐지 모델을 최초로 제안하며, 기존의 변환 방식 및 하이브리드 모델이 가진 문제점을 해결 - ANN-SNN 변환 없이 직접 학습된 순수 SNN 탐지 모델. - 기존의 하이브리드 모델과 달리 탐지 헤드도 SNN 방식으로 구현.
1. EMS-ResNet 설계 (전력 소비 감소) 기존 SNN 모델들은 일부 Shortcut Path에 Non-Spike연산이 포함됨 → 전력 소비 증가. EMS-ResNet은 완전한 스파이크 연산(Full-Spike Computing) 기반으로 설계되어 전력 소모를 줄임.
2. 이벤트 데이터 및 정적 이미지 모두 처리 가능 EMS-YOLO는 정적 이미지 + 이벤트 카메라 데이터 모두에서 높은 성능을 발휘.
2.3 Spiking Residual Networks
ANN-SNN 변환 방식의 연구들은 Deep SNN 학습을 위한 잔차 블록(Residual Block) 설계에 대해 거의 고려하지 않았다.
직접 학습(Direct Training) 방식에서는 잔차 네트워크를 설계하여 깊은 학습이 가능하도록 개선하는 연구들이 진행
EX) SEW-ResNet, MS-ResNet => 여전히 Non-Spike연산을 포함하고 있어 전력 소비 문제가 남아 있음.
SEW-ResNet (Spike-Element-Wise ResNet)
- 기존 ResNet의 개념을 적용하여, spike 기반 신호를 활용한 Residual Block 학습을 수행. - 하지만, Residual Path와 Shortcut Path가 모두 Non-Spike 연산을 포함. - 즉, Residual Connection에서 스파이크가 아닌 값들이 더해지면서 전력 소비가 증가.
MS-ResNet (Membrane-Shortcut ResNet)
- SEW-ResNet의 한계를 보완하기 위해 개발된 모델. - Residual Path에서는 스파이크 연산을 수행하여 SEW-ResNet보다 전력 효율성을 높임. - 하지만, Shortcut Path에서 여전히 Non-Spike 연산이 발생 → 객체 탐지에서는 에너지 소비 증가 요인.
EMS-YOLO
1. Full-Spike Computing 기존 SEW-ResNet과 MS-ResNet은 Shortcut Path에서 Non-Spike 연산이 포함됨. EMS-ResNet은 잔차 경로(Residual Path)뿐만 아니라 Shortcut Path에서도 스파이크 연산을 수행.
2. 전력 소비 최소화 기존 방식들은 Shortcut Path에서 Non-Spike 연산을 수행하기 때문에 불필요한 MAC 연산이 발생. EMS-ResNet은 Shortcut Path에서 완전한 스파이크 신호만 사용 → 불필요한 연산 제거 → 전력 소비 절감.
3. 더 깊은 네트워크 학습 가능 SEW-ResNet과 MS-ResNet은 비교적 얕은 네트워크(50~100층)에서 성능이 검증 EMS-ResNet은 Gradient Vanishing/Explosion 문제를 해결하여 더 깊은 네트워크 학습이 가능.
EMS-ResNet의 차별점 1. 기존 ResNet 기반 SNN의 한계를 해결하고, Shortcut Path에서도 스파이크 연산을 수행하는 최초의 모델 2. Full-Spike Residual Network 3. 불필요한 MAC 연산 제거 → 전력 소비 절감 4. Gradient Vanishing/Explosion 문제 해결 → 더 깊은 네트워크 학습 가능
3. The Preliminaries of SNNs
3.1. Spiking Neuron
뉴런(Neuron)
- 신경망의 기본 단위이며, 여러 시냅스 입력(Synaptic Inputs)을 받아서 의미 있는 신호(Spike)를 출력하는 역할 - 기존의 ANN에서는 뉴런이 시간적 특성을 무시하고, 단순히 공간적 정보만 전달 - 반면, SNN에서는 스파이킹 뉴런이 시간적으로 변화하는 막전위(Membrane Potential)를 유지하면서 신호를 처리
SNN에서 가장 널리 사용되는 뉴런 모델들은 다음과 같다. 1. Leaky Integrate-and-Fire (LIF) 모델 2. Hodgkin-Huxley (H-H) 모델 3. Izhikevich 모델
LIF Integrate-and-Fire (LIF) Model
- 생물학적 타당성과 연산 효율성 간의 균형이 가장 적절하여, SNN에서 가장 많이 사용됨.
1. 뉴런의 막전위(Membrane Potential)는 시간이 지남에 따라 점진적으로 감소(Leak). 2. 시냅스 입력(Synaptic Input)이 들어오면 막전위가 증가(Integrate). 3. 일정 임계값(Threshold)을 초과하면 뉴런이 스파이크를 발화(Fire). 4. 스파이크를 발화한 후에는 초기 상태로 리셋(Reset).
(1) LIF 뉴런의 수학적 모델 (2) 뉴런의 발화 여부(1)(2)
3.2 Training Strategies
- SNN에서는 spike가 Discrete(이산적)이고 Non-Differentiable(비미분적)이기 때문에 전통적인 Backpropagation을 사용할 수 없다.
- 역전파를 수행하려면 그래디언트(Gradient)를 계산해야 하는데, 계단 함수(Heaviside Function)는 미분이 불가능
Surrogate Gradient
- 스파이크 함수(Heaviside Step Function)는 미분이 불가능하지만, 이를 근사할 수 있는 부드러운(Smooth) 함수를 사용하여 역전파를 수행 - 스파이크 함수의 gradient를 근사하는 함수로 대체하여 학습을 진행 Surrogate Gradient
TDBN (Threshold-Dependent Batch Normalization)
- SNN 학습 과정에서 또 하나의 중요한 문제는 layer가 깊어질수록 Vanishing Gradient되거나 Exploding Gradient할 가능성이 크다는 점 - 기존의 Batch Normalization(BN) 기법을 SNN에 맞게 수정한 방법 - Spatial Inforamtion(공간 정보) + Temporal Information(시간 정보)를 모두 고려하여 뉴런을 정규화 - 뉴런의 Threshold(Vth)를 동적으로 조절하여 Vanishing Gradient를 방지 TDBN
3.3 Energy Consumption
- 기존의 인공 신경망(ANN)에서는 주로 부동소수점 연산(Floating-Point Operations, FLOPs)을 통해 연산 비용을 측정 - 하지만, SNN에서는 뉴런이 스파이크를 발화(Spike Firing)할 때만 연산이 수행되므로, 연산량과 에너지 소비를 측정하는 방식이 다르다.
- SNN의 에너지 소비는 일반적으로 시냅스 연산(Synaptic Operations, SyOPs) 및 누적 연산(Accumulation, AC)을 기반으로 계산
ANN에서는 모든 뉴런이 항상 활성화되어 연산 수행 → 연산량이 많고 전력 소모가 큼. SNN에서는 뉴런이 스파이크를 발화할 때만 연산 수행 → 에너지 효율적.
ANN의 연산 비용
- ANN에서의 주요 연산: MAC 연산 (Multiply-Accumulate) - 전체 연산 비용 = FLOPs의 개수에 따라 결정됨. - 모든 뉴런이 항상 활성화되므로 연산량이 많고 전력 소모가 큼.
SNN의 연산 비용
- SNN에서의 주요 연산: AC 연산 (Accumulation) - 뉴런이 스파이크를 발화할 때만 연산 수행 → 필요 없는 연산을 제거하여 에너지 절약 가능. - 따라서, 전체 연산 비용은 뉴런의 발화율(Firing Rate)에 따라 결정 SNN의 총 에너지 소비
- 각 뉴런의 발화율(Firing Rate)과 연산량에 의해 결정
- SNN은 기존 ANN과 달리 시간 정보를 유지하며 연산을 수행하며, 연산량이 적고 에너지 효율성이 높음. - Surrogate Gradient와 TDBN 기법을 활용 - EMS-YOLO는 기존 ANN보다 5.83배 적은 전력 소비로 동등한 성능을 낸다.
4. Method
4.1. Input Representation
SNN은 시간 정보(Temporal Information)를 활용하는 특징이 있기 때문에, 기존 ANN과는 다른 방식으로 입력 데이터를 변환하여 처리해야 한다.
Static Images Input
- 기존 ANN 기반 객체 탐지 모델들은 RGB 이미지(3채널 이미지)를 그대로 입력으로 사용 - SNN에서는 시간 정보를 포함한 입력 데이터가 필요하므로, 정적 이미지도 시간 축(Temporal Dimension)을 추가하여 여러 개의 프레임으로 변환 => 즉, 같은 이미지를 여러 타임 스텝 동안 입력하여 SNN이 시간 정보를 학습할 수 있도록 함.
Event-Based Input
- 프레임 단위가 아닌, 픽셀 단위에서 밝기 변화(Events)를 감지하여 데이터 생성 - 따라서, 기존의 프레임 기반 처리 방식과 다르게, 시간-공간적 정보(Spatio-Temporal Information)를 포함 - 픽셀별 밝기 변화가 일정 임계값을 넘으면 이벤트를 발생시킴 Event
- 이벤트 데이터는 비동기적(Asynchronous)으로 발생하며, 필요할 때만 저장되므로 저장 공간과 연산량을 줄일 수 있음 => 이벤트 데이터를 일정 시간 간격(Temporal Window)으로 나눠, 2D 이미지 형태로 변환
4.2. The Energy-Efficient Residual Block
Residual Block의 출력은 Residual Path와 Shortcut Path의 합으로 표현
기존 Deep SNN 학습을 위한 ResNet 구조를 적용하는 방법
SEW-ResNet (Spike-Element-Wise ResNet)
두 개의 스파이크 값이 합쳐지면서 비스파이킹 연산이 포함 - 기존 ResNet 구조를 유지하면서, Residual Path와 Shortcut Path 모두에서 스파이크 연산을 수행 - 하지만, 두 개의 스파이크를 합산하는 과정에서 비스파이킹(Non-Spike) 연산이 발생 - 즉, Shortcut Path에서 비스파이킹 연산이 포함됨으로써 추가적인 전력 소비가 발생 => MAC(Multiply-Accumulate) 연산이 발생
MS-ResNet (Membrane-Shortcut ResNet)
- SEW-ResNet의 문제를 개선하여, Shortcut Path에서의 MAC 연산을 줄이는 방향으로 설계 - Shortcut Path에서 Convolution 연산을 추가하여 차원 변화와 채널 수 변화를 처리 - 하지만, Shortcut Path에서는 여전히 비스파이킹 연산이 포함됨.
- 완전한 스파이크 기반 연산 (Full-Spike Computing) - EMS-ResNet은 Shortcut Path에서도 스파이크 연산만 수행하도록 설계 - Shortcut Path에서도 비스파이킹 연산을 제거하고, 모든 연산이 스파이크 기반으로 수행 - Shortcut Path에서 채널이 변경되는 경우에도 Concat 연산을 사용하여 정보를 유지하면서 연산량을 줄임 - MaxPool 연산을 사용하여 네트워크 내 연산량을 줄이고, 뉴런의 효율적인 정보 전달을 유도
SEW-ResNet / MS-ResNet / EMS-ResNet
4.3. The EMS-YOLO Model
- 우리의 목표는 주어진 정적 이미지(Static Image) 또는 이벤트 스트림(Event Stream)에서 객체의 분류(Classification)와 위치(Position)를 예측하는 것 입력 데이터
- 이를 통해 N개의 객체 정보를 포함하는 행렬 B를 계산 D는 EMS-YOLO가 수행하는 객체 탐지 연산을 의미
EMS-YOLO의 전체 구조
EMS-YOLO architecture
- 정적 이미지 및 이벤트 데이터 입력 가능 - 입력 데이터 X는 EMS-YOLO의 입력 레이어로 직접 전달
Backbone
- 특징 추출 네트워크 (Feature Extraction) - 첫 번째 Conv 레이어는 입력을 스파이크 신호로 변환하도록 학습 - LIF 뉴런은 입력 가중치를 통합(Ibtegrate)하고, 훈련된 발화 임계값(Firing Threshold)을 초과할 때 스파이크 신호 출력
# EMS-Modules
- 객체의 크기와 위치가 다르므로 다양한 차원(Dimensions) 및 채널 수(Number of Channels)에서 객체 특징을 추출하도록 설계 - 네트워크의 Robustness를 향
Detection Head
- 기존 YOLOv3-Tiny 탐지 헤드 → EMS-Blocks 기반 탐지 헤드로 대체 - 여러 개의 직접 연결된 컨볼루션 연산을 사용하는 기존 방식 대신, EMS-Blocks를 적용하여 탐지 헤드의 성능을 최적화 - 객체 탐지는 SNN 모델을 활용한 회귀(Regression) 문제로 간주될 수 있다. - 이때, 주요 도전 과제는 스파이크 신호(Spike Trains)에서 추출한 특징을 정확한 연속값(Continuous Value)으로 변환하는 것 - EMS-YOLO 모델은 교차 엔트로피 손실 함수(Cross-Entropy Loss Function)로 학습
4.4. Analysis of Gradient Vanishing/Explosion Problems
GNE
- SNN의 경우 시간 차원이 추가되면서 Gradient가 더욱 빠르게 감쇠될 위험이 있다. - Gradient Norm Equality(GNE) 이론을 기반으로 EMS-ResNet이 Gradient Vanishing/Explosion을 방지할 수 있다. - GNE 이론에서는 각 블록의 Jacobian 행렬이 아래 조건을 만족해야 한다.
=> 이 조건이 성립할 경우, 네트워크는 "Block Dynamical Isometry"를 만족하며 그래디언트 소실/폭발을 방지
Lemma(보조 정리)
Multiplication (곱셈 정리)
- 뉴럴 네트워크가 여러 개의 블록(Block)으로 구성될 때, 전체 네트워크의 그래디언트 흐름을 분석하는 원리. - 블록별 야코비안 행렬이 독립적인 경우, 전체 네트워크의 그래디언트 흐름은 개별 블록의 그래디언트 변화량의 곱으로 표현됨.
Addition (덧셈 정리)
- 병렬 구조(Parallel Connection)에서의 그래디언트 변화량을 설명. - 야코비안 행렬이 병렬 연결될 경우, 전체 그래디언트 변동량은 개별 블록의 변동량의 합으로 표현됨.
General Linear Transform (일반 선형 변환)
- 풀링(Pooling), 업샘플링(UpSampling), Concat 연산도 일반 선형 변환으로 간주할 수 있음. - 이는 EMS-ResNet의 구조에서 그래디언트 소실을 방지하는 역할을 수행.
Proposition
- 입력 데이터의 2차 모멘트(Second Moment)를 조절함으로써 위 조건을 만족할 수 있음. - 즉, EMS-Blocks가 그래디언트 소실/폭발 문제를 방지할 수 있도록 설계됨.
- MS-Block은 그래디언트 증가를 유발할 수 있음.
- 그러나, EMS-Blocks가 MS-Block 사이에 존재함으로써 이러한 그래디언트 증가를 효과적으로 제어.
- EMS-ResNet은 기존 SNN 모델과 달리, Shortcut Path에서도 완전한 스파이킹 연산을 수행하여 전력 소비를 줄이고 그래디언트 안정성을 향상시킴. - EMS-YOLO는 YOLO 아키텍처를 기반으로 SNN을 적용한 최초의 객체 탐지 모델로, 입력부터 출력까지 스파이킹 뉴런을 활용하여 Bounding Box 좌표를 예측하고 학습 가능. - Gradient Norm Equality(GNE) 이론을 기반으로 EMS-ResNet의 그래디언트 소실 및 폭발을 방지하고, EMS-Blocks를 활용해 깊은 네트워크에서도 안정적인 학습이 가능하도록 설계됨.
-데이터셋 (Datasets) PASCAL VOC (Visual Object Classes) MS COCO (Common Objects in Context) Gen1 Automotive Detection Dataset (이벤트 기반 데이터셋)
- 비교 모델 (Baseline Models) YOLOv3-Tiny (CNN 기반 객체 탐지 모델) Spiking-YOLO (기존 SNN 기반 탐지 모델) EMS-YOLO (제안 모델)
5.2. Performance Evaluation
객체 탐지 정확도 (Detection Accuracy)
- 평균 정밀도 (mAP, Mean Average Precision) 기준으로 모델 성능 비교. - EMS-YOLO는 기존 CNN 기반 YOLO 모델과 비슷한 정확도를 유지하면서도, 전력 소비가 훨씬 낮음을 확인.
에너지 소비 (Energy Consumption)
- SNN의 주요 장점은 에너지 효율성이 높은 점이므로, 각 모델의 전력 소비량을 비교. - EMS-YOLO는 기존 CNN 기반 YOLO 모델 대비 5.83배 낮은 전력 소비를 기록. - Spiking-YOLO보다도 에너지 효율성이 높으며, 연산량을 줄이면서도 정확도를 유지함.
5.3. Ablation study
EMS-YOLO의 성능 향상에 기여하는 주요 구성 요소를 분석
Different Residual Blocks
- EMS-Block의 구조적 우수성을 탐구하기 위해, 우리는 Gen1 Dataset을 기반으로 비교 실험을 수행
- 모든 실험은 50 Epoch 동안 훈련되었으며, 배치 크기(Batch Size)는 64로 설정
- 실험 결과, 완전 스파이킹(Full-Spike) EMS-ResNet의 성능이 기존 비스파이킹(Non-Spike) ResNet들과 유사함을 확인 - 또한, 네트워크의 희소성(Sparsity)도 유지됨을 보였다.
- Equation 6을 이용하여 네트워크의 에너지 소비량을 계산 Equation 6
- 첫 번째 인코딩 레이어의 컨볼루션 연산을 제외한 에너지 소비량을 측정 Result
=> EMS-ResNet은 기존 ANN-ResNet18 대비 최대 4.91배의 에너지 효율성을 달성
Numbers of Residual Blocks
- Gen1 Dataset을 활용하여 EMS-Res10, EMS-Res18, EMS-Res34의 성능을 비교
- 네트워크 규모가 커질수록(ResNet이 깊어질수록), 특징 추출(Feature Extraction) 성능이 향상됨. - Figure 3에서 확인할 수 있듯이, 더 깊은 네트워크 구조가 더 강력한 성능을 보임. => Residual Blocks 개수를 늘릴수록 객체 탐지 성능이 향상
Size of Time Steps
- EMS-ResNet10을 활용하여, COCO2017 Dataset에서 타임 스텝 크기(T)를 1, 3, 5, 7로 변경하며 성능 분석
- 타임 스텝이 길수록 객체 탐지 정확도가 증가 (Figure 4 참조) Result - 초기 모델을 T=1에서 학습한 후, 이를 사전 학습 모델(Pre-Trained Model)로 활용하여 다중 타임 스텝 훈련 시, 훈련 시간이 단축
- EMS-YOLO는 기존 CNN 기반 YOLO 모델과 비슷한 객체 탐지 정확도를 유지하면서도, 5.83배 적은 전력 소비를 기록함. - EMS-ResNet은 기존 ANN-ResNet18 대비 최대 4.91배 에너지 절약이 가능하며, 유사한 성능을 유지 - Residual Block개수가 증가할수록 특징 추출 능력이 향상되며, 더 깊은 네트워크에서 성능이 개선 - 타임 스텝이 길어질수록 객체 탐지 성능이 향상되며, 사전 학습 모델을 활용하면 훈련 시간을 단축할 수 있음.
6. Conclusion
- 본 연구는 최초로 SNN을 직접 학습하여 객체 탐지 작업에 적용 - EMS-ResNet을 설계하여, Shortcut Path 및 Residual Connection에서 불필요한 MAC 연산을 제거하여 에너지 효율성을 높임. - EMS-YOLO는 기존 ANN YOLO 모델과 유사한 성능을 달성하면서도, 짧은 타임 스텝 내에서 정적 이미지 및 이벤트 기반 데이터 모두에서 우수한 성능을 보임.