-Model-Based Learning
-> training data를 이용하여 모델 구축
-> model을 사용하여 예측
-Instance-Based Learning
-> hyperparameters결정
-> 새로운 instance를 training data와 비교하며 예측
=> training 시간이 적게 걸리지만 예측에 더 많은 시간 소요, 시간이 지남에 따라 점진적으로 training data를 사용할 수 있을 때 유리
-K-nearest Neighbors
-> (Instance-Based Learning) 새로운 데이터 포인트를 예측하기 위해 training data set에서 가장 가까운 이웃을 찾는다.
-> 예측은 가장 가까운 이웃에 대한 알려진 출력의 집계
Classification

Regression

-How to select K
Distance Metric

1. Euclidean distance: 가장 흔하게 사용(L2 distance), 최단거리

*Minkowski distance: Euclidean distance의 일반화된 형태
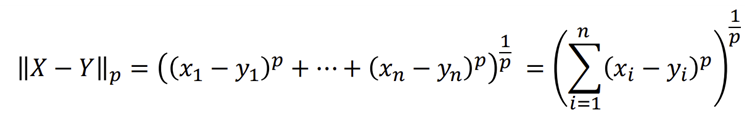
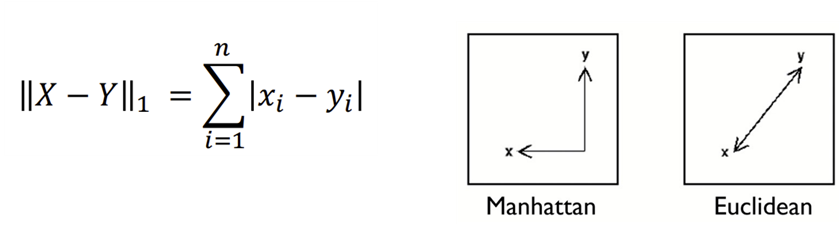
2. Manhattan distance: Euclidean 거리가 Manhattan거리보다 항상 작거나 같다, (L1-distance)
3. Mahalanobis distance: 데이터 분포를 고려한 거리 측정
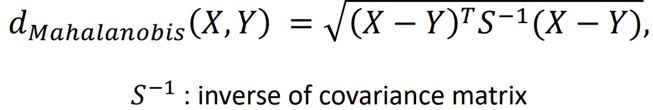
*공분산 (S)


-> M은 오히려 B가 A보다 멀다 (분포로부터 거리)
4. Correlation distance: 두 데이터 포인트의 상관관계를 가지고 평가

-Small K: 로컬 구조를 데이터에 캡쳐(노이즈도 포함)
-Larger K: 더 smmothong, 더 적은 노이즈 다만 로컬 구조를 놓칠 수 있다.


'3-1 > Data Mining' 카테고리의 다른 글
| 7주차-SVM(1) (3) | 2024.05.11 |
|---|---|
| 6주차-Random Forest (0) | 2024.05.11 |
| 5주차-Decision Tree (0) | 2024.05.11 |
| 4주차-Linear Models (1) | 2024.05.11 |
| 2주차-Supervised Learning (1) | 2024.05.11 |