- LeNet-5

-해당 신경망은 요즘에 비하면 상대적으로 적은 변수를 가진다.
- sigmoid, tanh O/ ReLu X
- padding X
- 60k parameters
=> 높이(nh), 너비(nw)는 감소/ 채널(nc)은 증가
- AlexNet

- LeNet에 비해서 굉장히 많은 변수를 가진다.
- ReLu를 활성화 함수로 사용
- padding O (same)
- 60M parameters
- multipul GPU를 사용, Local response normalization
- VGG-16

- AlexNet의 복잡한 구조에 비해 VGG Net은 더 간결한 구조
- 모든 합성곱 연산은 3X3 필터, padding은 2, stride는 1, 2X2 max pooling
- ~138M parameters (네트워크 크기가 커짐)
=> 높이(nh), 너비(nw): 매 max pooling마다 1/2씩 감소 / 채널(nc)는 2배 혹은 3배로 증가
- Residual block

- Main path: 모든 층을 지나는 연산과정
- skip connection/ short cut: z^{[l+2]}에 비선형성 적용 전에 a^{[l]}을 더하고 이것을 다시 비선형성을 적용
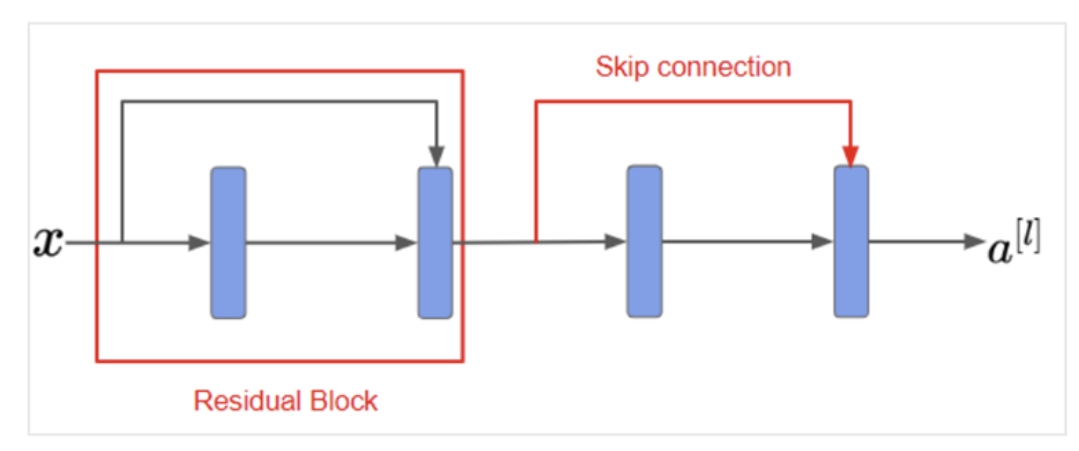
- Residual Block: a^[l]을 더해서 다시 활성화 함수에 넣는 부분
- short cut/ skip connection: a^[l]에 정보를 더 깊은 층에 전달하기 위해 일부 층을 뛰어 넘는 것


- One-by-One Convolution (network in network)

높이, 너비는 동일/ 채널은 감소
- Motivation for inception network

Inception network의 생각은 필터의 크기나 풀링을 결정하는 대신 전부 다 적용해서 출력을 합침
=> 네트워크 스스로 변수나 필터 크기의 조합을 학습

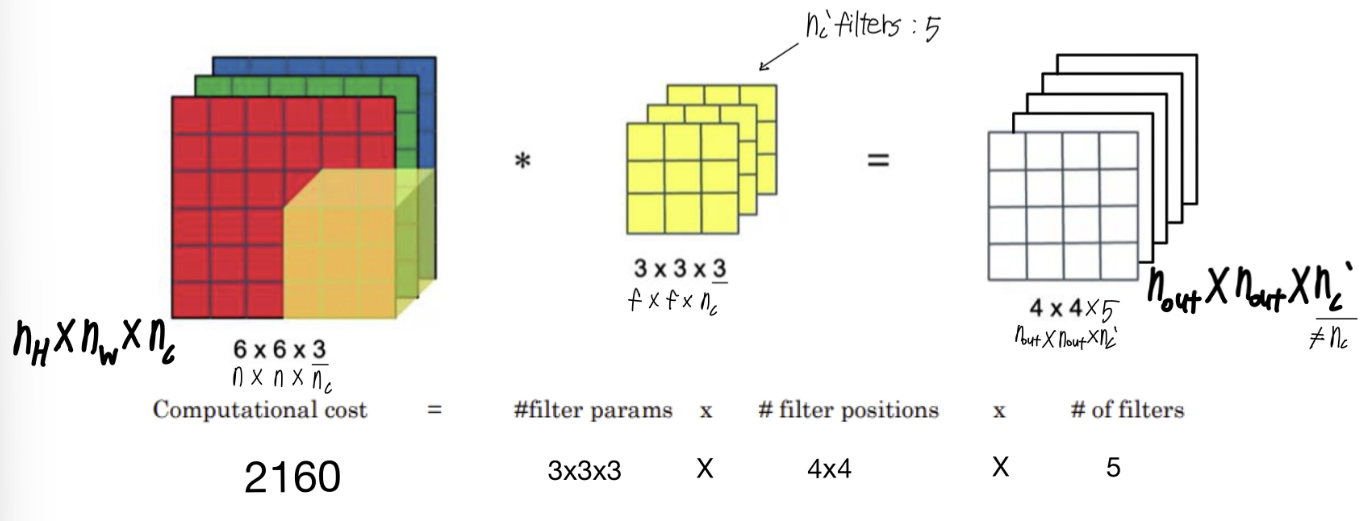
계산비용: 28X28X32 X 5X5X192 = 120M
* Using 1X1 convolution

계산비용: 28X28X16 X 1X1X192 = 2.4M
28X28X32 X 5X5X16 = 10.0M
+ = 12.4M
=> 계산비용 줄어듬
- 여기서 사용된 1X1 합성곱 층: 병목층
- Inception Module (GoogLeNet)

-첫번째 conv: 계산량 줄임/ 두번째 conv: channel사이즈 줄임

- 여러 인셉션 블록이 계속 반복
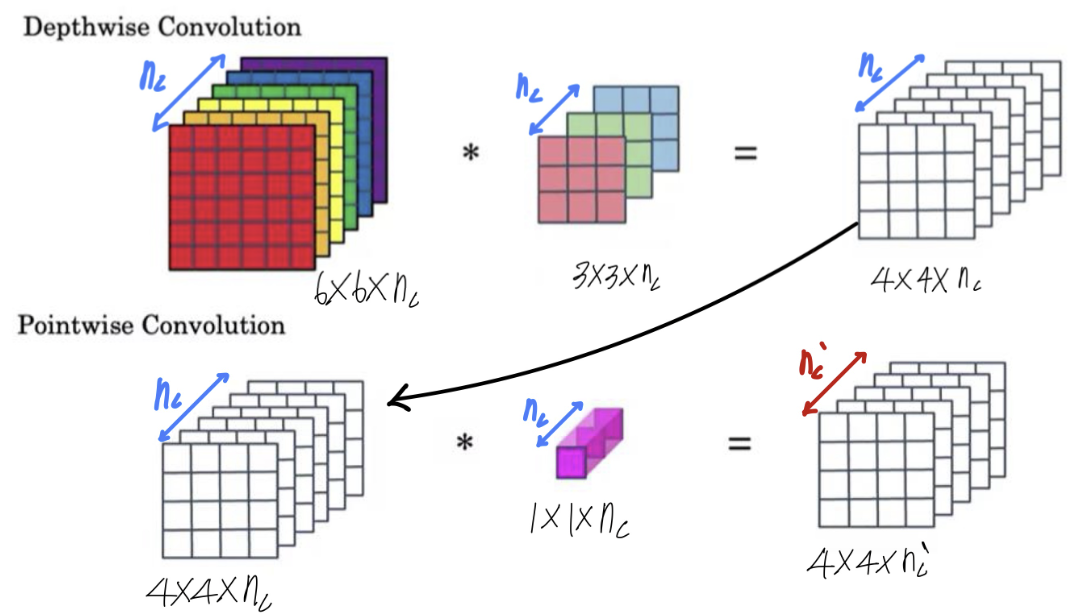
- Normal Convolution
- Depthwise Separable Convolution

- Depthwise Convolution

- Pointwise Convolution


=> Depthwise Separable Convolution
- Mobile Net

- Transfer Learning

데이터 증강
1. Mirroring (수직축 대칭)
2. Random Cropping (데이터의 일부분을 무작위로 자른다)
3. Rotation(회전) , Shearing (비틀기), Local warping(부분왜곡)
4. Color shifting (색변환)
'3-1 > Deep Learning' 카테고리의 다른 글
| 13주차-Recurrent Neural Networks (0) | 2024.06.01 |
|---|---|
| 12주차-Object Detection (0) | 2024.05.30 |
| 9주차-ML Strategy (0) | 2024.05.11 |
| 7주차-Convolutional Neural Networks (1) | 2024.05.11 |
| 6주차-Hyperparameters and Batch Norm (1) | 2024.05.11 |