- Sequence data < >
EX)

- Notataion
Seqence data(< >), Tx, Ty(x와 y에 대한 시퀸스 데이터 길이)


Q) standard network(일반적인 신경망)으로는 텍스트 훈련이 잘 되진 않는다. 이유는?
A) 1. 입력과 출력의 길이가 training data마다 다르다.
2. 텍스트의 서로 다른 위치에서 학습된 feature가 공유되지 않는다.
- RNN(Recurrent Neural Network)
입력과 출력을 시퀸스 단위로 처리하는 시퀸스 모델
은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보냄.

각 시점 단계에서 파라미터를 공유한다. (Wax, Waa, Wya)
Notation: W는 가중치, a는 산출되는 대상, x는 곱해지는 대상

- Forward Propagation

active function은 tanh/ ReLU 사용/ 예측값 계산은 Sigmoid사용
- Simplified RNN notation

=>activation과 vocabulary의 개수를 주고 size구하기
activation 100개, vacabulary 10,000개 => size 100x10,100
- Forward propagation and Backpropagation

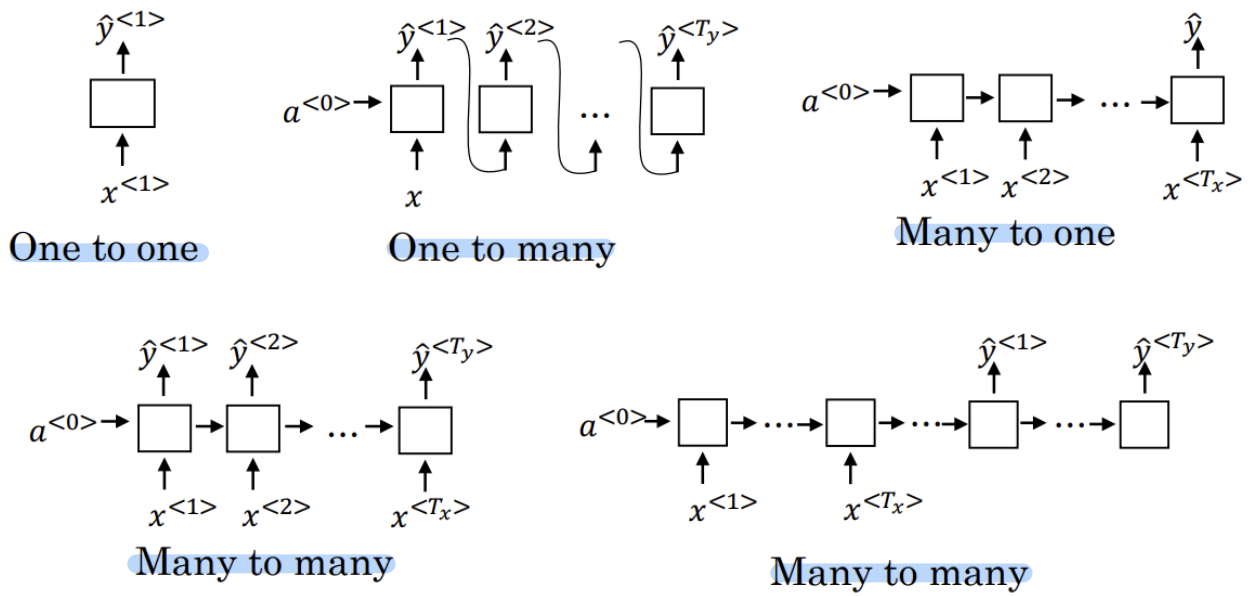
- RNN architecture
1. Many to many

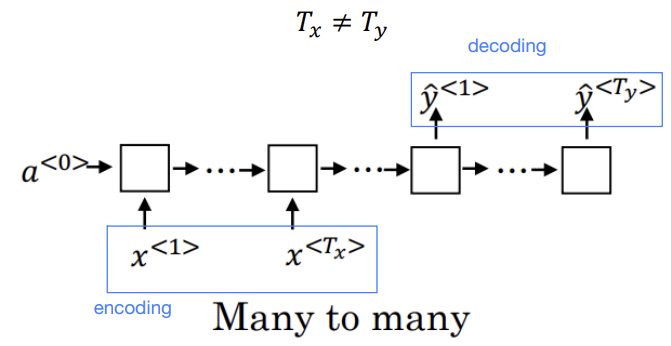
EX) Machine translation
2. Many to one

EX) 영화평점
3. One to one

4. One to many

EX) music generation
- Summary
- RNN model
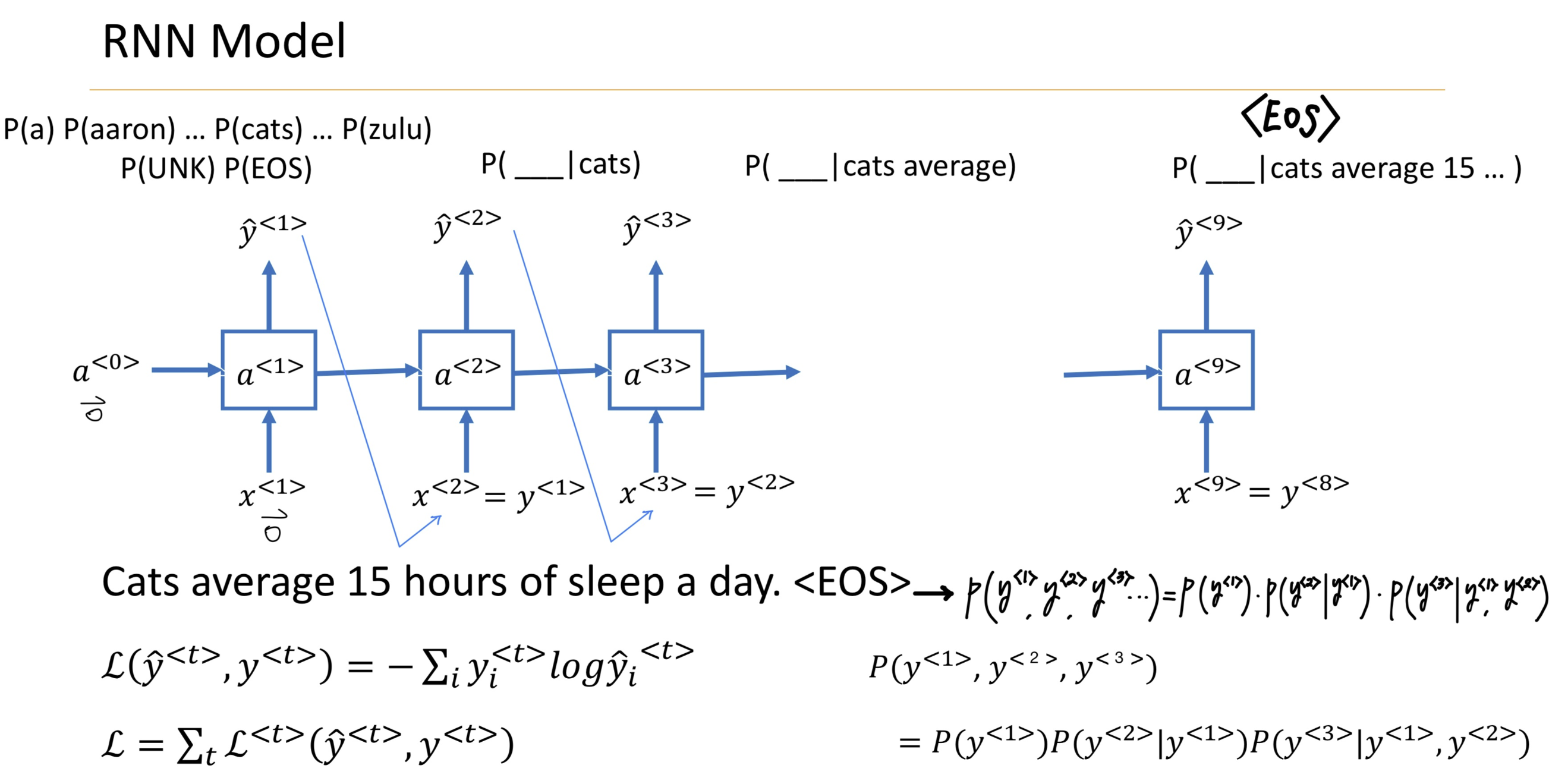
이전의 결과값을 이어서 계산 (y<1> = x<2>)
- Sampling a sequence from a trained RNN
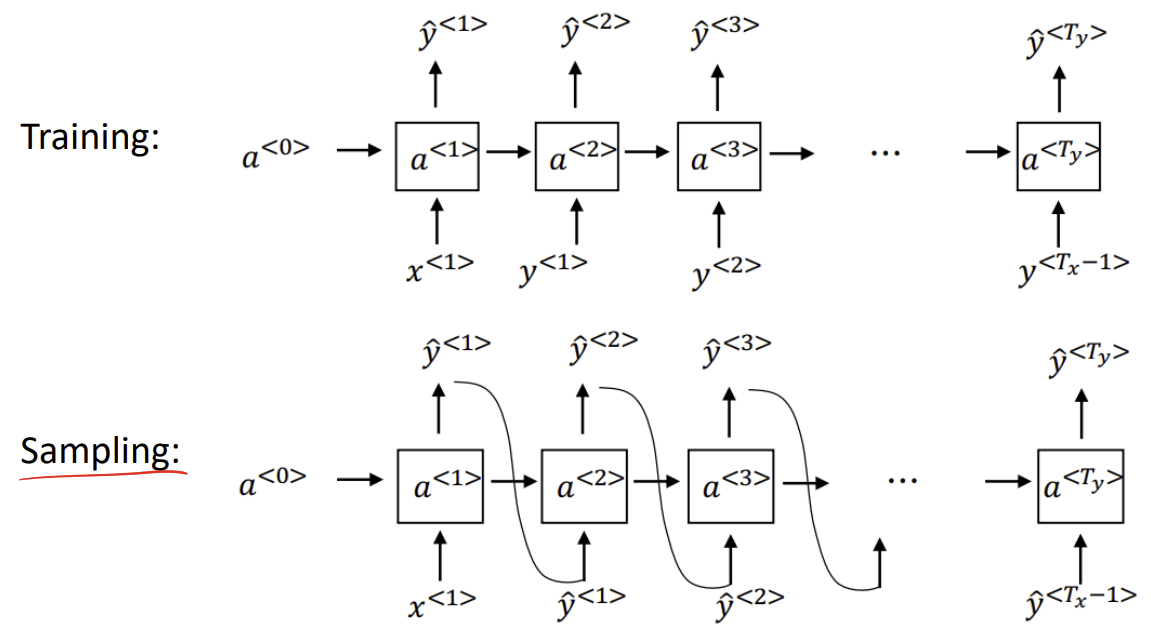
Sampling: 각 예측값은 무작위로 샘플링하여 소프트맥스 분포(Y의 분포를 따름)에 따라 값을 구한다.
RNN은 activation function을 다음 신경망에서 계산/ Sampling은 T번째 sampling 데이터를 T+1번째 sampling에 적용
- Character-level language model

장점: unknown word 신경 쓸 필요가 없다. (자유도가 높아짐)
단점: 계산량 많아짐, parameter 트레이닝 어렵다.
- Vanishing gradients with RNNs

RNN은 깊은 신경망일수록 과거의 결과값을 제대로 훈련하기 어렵다.
역전파를 진행할 때 교육효과가 떨어지는 vanishing gradients문제가 생김.
- RNN unit
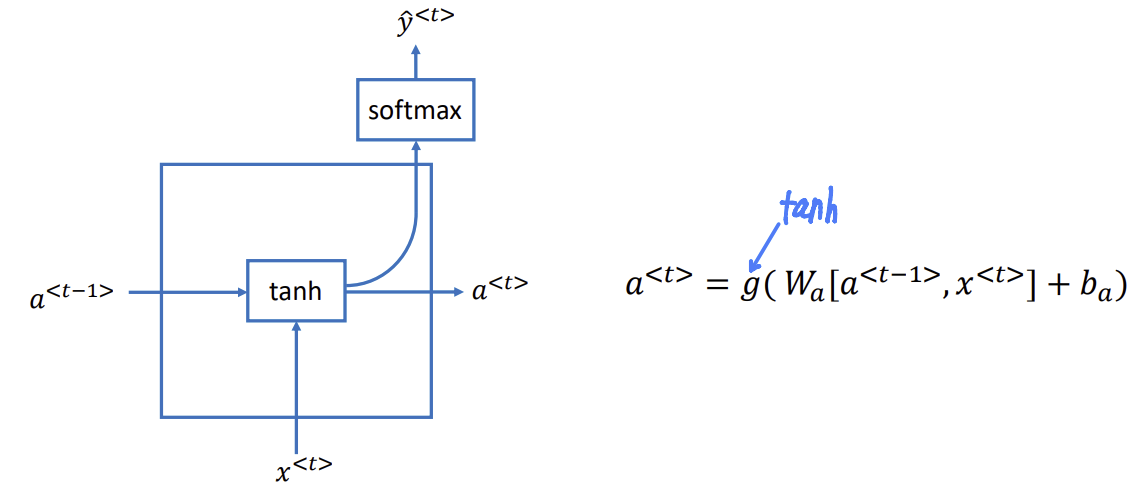
T-1번째 활성화 결과가 T번째 입력값과 계산되어 T번째 활성화 값이 된다.
- GRU(simplified): Gated Recurrent Unit

update gate: 얼마나 이전 상태를 유지하고 새로운 정보를 반영할지를 결정
- Full GRU

- GRU and LSTM

- LSTM

- Bidirectional RNN(BRNN)
양방향 RNN모델은 T번째 예측값이 1,2,..,T-1과 더불어 T+1, T+2,...N번째까지 영향을 받는 것을 계산하기 위함.

- Deep RNNs

- Word embedding
단어의 특징을 판단하여, 이에 따라 각각의 값을 부여.
=> 벡터들이 단어의 성질을 나타내는 벡터로 정리/ 서로 다른 단어간의 유사성을 판단



- Named entity recognition example

- Transfer learning and word embeddings
- 대규모 text corpus(1-100B words)에서 word embedding학습 (또는 온라인에서 사전 학습된 embedding을 다운로드)
- 작은 training set를 가진 새로운 작업으로 embedding 전이
- 선택사항: word embedding을 새로운 데이터로 미세 조정
- word embedding 유용한 경우/ 덜 유용한 경우
유용한 경우: 많은 NLP 작업- named entity recognition, text summarization, parsing
덜 유용한 경우: language modeling, machine translation (많은 양의 전용데이터가 필요함)
- Analogies


- Cosine similarity

- Embedding matrix

'3-1 > Deep Learning' 카테고리의 다른 글
| 14주차-Natural Language Processing (0) | 2024.06.07 |
|---|---|
| 12주차-Object Detection (1) | 2024.05.30 |
| 10주차-Deep CNN models (0) | 2024.05.15 |
| 9주차-ML Strategy (0) | 2024.05.11 |
| 7주차-Convolutional Neural Networks (1) | 2024.05.11 |