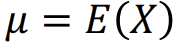- X라는 유한하거나 셀 수 있는 무한집합을 고려한다. - 이산확률변수 X의 경우, 사건 X=x의 확률은 P(X=x) or P(x)로 나타내며, x는 X의 원소이다. - 여기서 P()는 확률 질량 함수(PMF, Probability Mass Function)라고 한다.
확률질량함수(PMF): 확률 변수가 특정 값을 가질 확률을 나타내는 함수.
EX) 주사위, 동전 던지기 => X = {1,2,3,4,5,6}, X = {0,1}
연속확률변수(Continuous RV)
- X가 어떤 불확실한 연속량이라고 가정. - X가 구간 a<=X<=b에 있을 확률은 다음과 같이 계산 - A = (X<=a), B = (X<=b), W = (a<X<=b) - P(B) = P(A) + P(W) - P(W) = P(B) - P(A) -모든 x에 대해 f(x)>0이며, 밀도함수는 1로 적분된다.
누적분포함수(CDF)
확률밀도함수(PDF)
EX) 키(Height)
가우시안 (정규) 분포(Gaussian (Normal) Distribution)
통계학 및 머신러닝에서 가장 널리 사용되는 분포
표기
평균(최빈값)분산
정규분포의 누적분포함수(CDF)
EX)
결합확률(Joint Probability)
EX)
조건부확률(Conditional Probability)
사건 B가 참일때, 사건 A의 조건부 확률은 다음과 같다.
EX)
=> P(B|A=0) =! P(A=0|B) 서로 다르다!
베이즈정리(Bayes Rule)
EX)
Example1
- 어떤 사람이 암이 있는 경우, 테스트가 양성일 확률은 0.8 - 이 테스트를 받은 후, 테스트 결과가 양성일 때 암에 걸렸을 확률은 얼마일까? 0.8일까? => 아니다!
Example2
=> 우연치 않게 18/20으로 같다.
Example3
- 호텔 A, B, C 중 하나를 무작위로 선택한 후, 그 호텔을 방문한다. - 각각의 호텔이 오션 뷰 방을 제공할 확률은 호텔 A가 75%, 호텔 B가 25%, 호텔 C가 50%이다. - 오션 뷰 방을 받았을 때, 어느 호텔을 방문했는지 찾으시오.
=> A, B, C방을 받았을 때 오션 뷰일 확률
오션 뷰 방을 받을 확률 자체는 중요하지 않다!
=> 오션뷰를 받았을 때, 각각 A, B, C방일 확률
생성모델 분류기(Generative Classifier) - MAP
데이터 생성 방법을 P(x|y = c)와 클래스 사전 확률 P(y = c)로 지정
다음과 같이 클래스를 결할 수 있다.
이러한 접근 방식을 Maximum a posterior(MAP)라 한다.
베이지안 개념 학습(Bayesian Concept Learning)
모델을 특성화하는 parameter vector θ 포함
Number Game Example
- 간단한 산술 개념 C를 선택. 예를 들어 "소수" 또는 "1과10사이의 숫자"와 같은 개념을 선택 - 개념 C에서 무작위로 선택된 일련의 양의 예제 D={x1,x2,...,xn}를 제공한다. 그런 다음 새로운 test case x tilda가 C에 속하는지 묻는다. 즉 x tilda를 분류하라고 요청. - 간단하게 모든 숫자가 1에서 100 사이의 정수라고 가정 - 이제 "16"이 그 개념의 양의 예제라고 알려준다. 이 경우 다른 양의 예제는 무엇인가?
17? 6? 32? 99?
"16"을 말했을 때, 17,6,32는 99보다 가능성이 높다. 이러한 "가능성의 정도"를 다음과 같이 표현한다.
이를 후방예측분포(posterior predictive distribution)이라 한다.
=> 4, 8, 32등은 비교적 높은 가능성을 가지는 반면, 99는 낮은 가능성을 보임
"8, 2, 64"가 추가로 제공되었다. 즉, D = {2, 8, 16, 64}이다. 이제 숨겨진 concept이 "2의 거듭제곱"이라고 말할 수 있다. => 귀납(induction)
=> 2, 4, 8,16, 32, 64등의 값에 높은 확률을 부여함.
D = {16, 23, 19, 20}에 대해 일반화 경향(generalization gradient)이 다르게 나타남.
=> 16, 19, 20, 23이 높은 확률을 보임.
We Should Emulate in Machine For
귀납(induction)을 위해, 개념 H의 가설 공간을 정의한다.
예를 들어: 홀수, 짝수 1에서 100사이의 모든 숫자, 2의 거듭제곱, 특정 숫자로 끝나는 모든 숫자 등
데이터 D = {16}을 본 후
가능한 concept이 많이 있다. 이를 결합하여 새로운 test case x tilda가 C에 속하는지 예측하려면?
데이터 D = {16, 8, 2, 64}을 본 후
왜 "2의 거듭제곱"이라는 규칙을 선택했나? 왜 "모든 짝수" (likelyhood때문에)나 "32를 제외한 2의 거듭제곱"(prior때문에)이라고 하지 않았나?
=> 우리는 h_two = "2의 거듭제곱"을 선택할 가능성이 높고, h_even = "짝수"는 선택할 가능성이 낮다.
핵심은 "Suspicious coincidences"(의심스러운 우연의 일치)를 피하는 것이다. => 만약 실제 개념이 짝수라면, 왜 우리가 본 숫자들이 모두 우연히도 2의 거듭제곱일까?
Quantifying Likelihood
강한 샘플링 가정하에
독립적으로 N개의 항목을 h에서(복원 샘플링과 함께) 샘플링할 확률은 다음과 같다.
Occam's razor
"모델이 D와 일치하는 가장 단순한(작은) 가설을 선호한다."는 것을 형식화한 것.
EX)
D = {16}일 때: P(D|h_two) = 1/6, P(D|h_even) = 1/50 => 이 경우 likelihood는 h_two가 h_even보다 크다.
D = {16, 8, 2, 64}일 때: P(D|h_two) = (1/6)^4, P(D|h_even) = (1/50)^4 => 이는 5000:1의 likelihood 비율을 나타냄
이것은 의심스러운 우연의 일치(suspicious coincidence)의 정도를 정량화한다.
Revisiting Posterior Estimation
Necessity of Prior
h_two-32= "32를 제외한 2의 거듭제곱"의 likelihood가 h_two= "2의 거듭제곱"보다 높다.
h_two-32= "32를 제외한 2의 거듭제곱"은 개념적으로 부자연스럽게 보인다.
우리는 이를 P(h)로 반영하여 과적합(overfitting)을 방지해야 한다.
P(h)는 주관적이어서 Bayesian reasoning을 불안정하게 만들 수 있다.
하지만 P(h)는 데이터에 대한 배경 지식을 반영하기 때문에 유용하다.
EX)
D = {120, 150, 90, 140}에 대해, 20 VS118을 고려해보자. Background 1) 데이터가 산술 규칙에 따라 선택됨 => "0"으로 끝남 (20) Background 2) 데이터가 인간의 혈압 수준을 나타냄 => 사람 혈압(118)
데이터에 대한 다른 배경 지식이 P(h)를 결정하며, 이는 머신러닝의 효율성을 크게 향상시킨다.
Prior Example for Number Game
=> "2의 거듭제곱, 37을 더함"과 "32를 제외한 2의 거듭제곱" 같은 비자연스러운 개념들은 매우 낮은 사전 확률을 가진다.
사전확률은 training set 이전에 획득되어야 한다.(Should be obtained “prior” to training set) => 사전 지식이나 배경 정보를 기반으로 사전 확률을 설정한 후, 모델을 훈련시켜야 한다.
Finally, Posterior
D = {16}일 때
1. posterior: "2의 거듭제곱" 가설이 가장 높은 확률을 가진다. 2. likelihood: "2의 거듭제곱" 가설이 가장 높은 확률을 가진다. ({16}이 이 가설에 잘 맞기 때문) 3. Prior: "짝수", "홀수" 가설이 가장 높은 확률을 가진다. "2의 거듭제곱" 가설은 상대적으로 낮은 확률을 가진다.
D ={16, 8, 2, 64}일 때
1. Posterior: "2의 거듭제곱" 개념이 가장 높은 값을 가지며, 이는 데이터 {16,8,2,64}가 이 개념에 잘 맞기 때문이다. 2. likelihood: "2의 거듭제곱" 개념이 가장 높은 값을 가지며, 이는 데이터 {16,8,2,64}가 이 개념에 잘 맞기 때문이다. "짝수" 개념과 "32를 제외한 2의 거듭제곱" 개념은 likelihood가 매우 낮다. 3. Prior: "짝수"와 "홀수" 개념이 가장 높은 사전 확률을 가지며, "2의 거듭제곱" 개념의 사전 확률은 상대적으로 낮다. "32를 제외한 2의 거듭제곱" 개념의 사전 확률은 매우 낮다.
MAP Estimate VS MLE
MAP 추정값
likelihood term은 N에 대해 기하급수적으로 의존하고, Prior은 일정하게 유지되므로, 데이터가 많아질수록 MAP추정값은 MLE로 수렴한다.