SK AI Data Academy 1기 중급/[SK하이닉스] DRAM 내부 회로의 파형 예측
04. 시계열 모델을 통한 파형 예측
Donghun Kang2024. 7. 21. 16:40
시계열 데이터
- 일반적인 회귀 모델은 데이터가 서로 독립적이라 가정 - 시계열 데이터는 데이터 간의 시간적 상관 관계를 가짐 - 시계열 모델은 데이터 간의 시간적 패턴을 모델링 가능
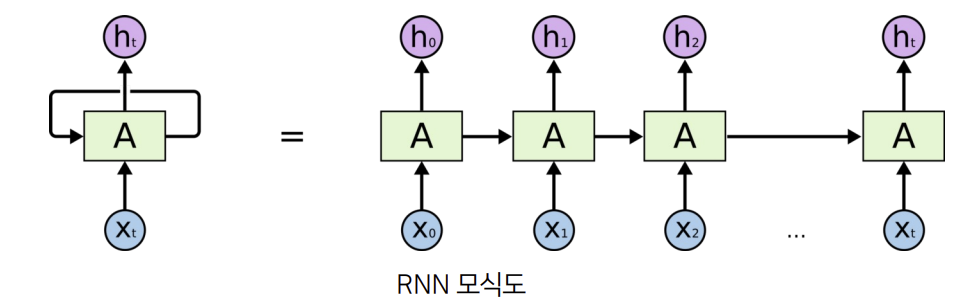
RNN(Recurrent neural network)
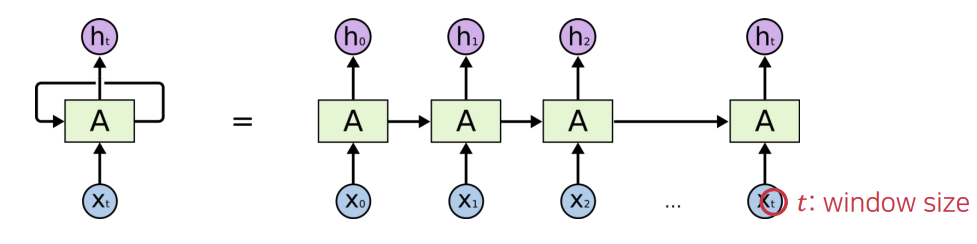
- 시계열 데이터에 적용할 수 있는 대표적인 신경망 모델 - t+1 시간 동안의 입력 X0,...,Xt를 RNN의 신경망 A에 입력할 때, A는 다음의 식에 따라 h0,...,ht를 출력.
- hi는 i시간 동안의 입력값의 패턴 정보를 가지게 되고, 최종 출력 ht는 연속된 데이터의 시간적 패턴을 모델링
RNN 모델의 구현
- RNN에 데이터를 적용하기 위해 읽어온 데이터를 시계열 데이터 형식으로 변환
- Pandas로 읽어온 데이터의 shape은 다음과 같다.
- Many to one 문제의 RNN 모델 학습에 사용되는 데이터는 다음과 같은 shape이어야 함.
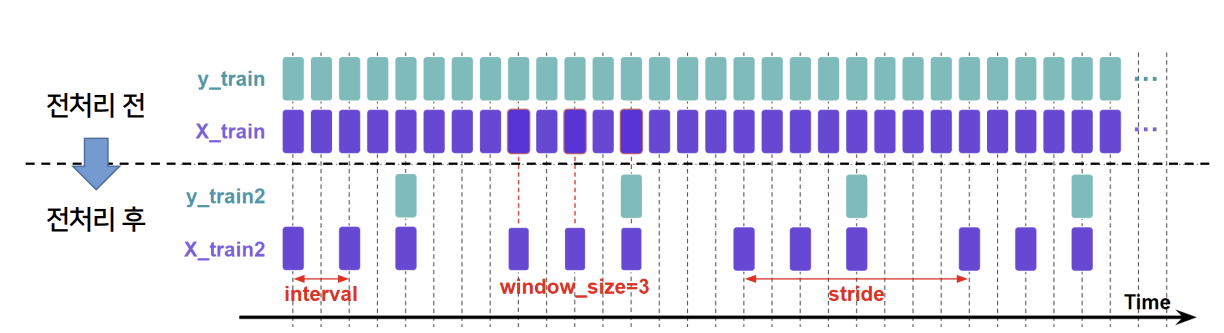
Window size: 하나의 data sequence를 구성하는 시간별 데이터의 개수이다.
- 읽어온 데이터를 전처리 해주어야 함.
1. Window size를 조절하여 sequence의 길이를 조절함.
2. Interval을 조절하여 window내 데이터 사이 시간 간격을 조절함.
3. Stride를 조절하여 window간의 시간 간격을 조절함.
# 읽어온 데이터를 시계열 데이터로 변환
def process_data(X, y, window_size, stride, interval):
X_ = []
for i in range(0, window_size * interval, interval):
X_.append(X[i:len(X) - window_size * interval + 1 + i])
X_ = np.asarray(X_)[:,::stride].transpose().reshape(-1, window_size, 1)
retuen X_, y[num_sequences * interval-1::stride]
- 하나의 data sequence 시각화
- Pytorch를 이용하여 RNN구현
<모델 정의>
import torch
Class RNN(torch.nn.Module): # 모델 정의
def __init__(self, ...):
super(RNN, self).__init__()
self.rnn = torch.nn.RNN(...) # RNN 레이어 추가
self.fc = torch.nn.Linear(...) # 출력 MLP 레이어 추가
def forward(self, X): # 모델 forward pass
y, hidden_states = self.rnn(X) # hidden state는 0-vector로 초기화
y = self.fc(y[:,-1])
return y
<모델 학습>
import torch
criterion = torch.nn.MSELoss() # loss function 정의
optimizer torch.optim.Adam(model.parameters(), lr=0.01) # optimizer 정의
for epoch in range(epochs):
model.train() # model의 gradient 계산하도록 설정
for it, data in enumerate(dataLoader):
X, y = data
pred model(X)
loss = criterion(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
<모델 예측>
import torch
model.eval() # model의 gradient 계산하지 않도록 설정
pred = model(X_test)
RNN 모델의 한계
- sequence가 길어지면, 예전 데이터를 잘 기억하지 못한다.
- Short-term memory problem - Gradient vanishing problem
LSTM( Long short-term memory)
- 대표적인 RNN 기반 신경망 모델 - RNN의 short-term memory를 완화 - 중요한 부분만 기억하고, 중요하지 않은 부분은 삭제
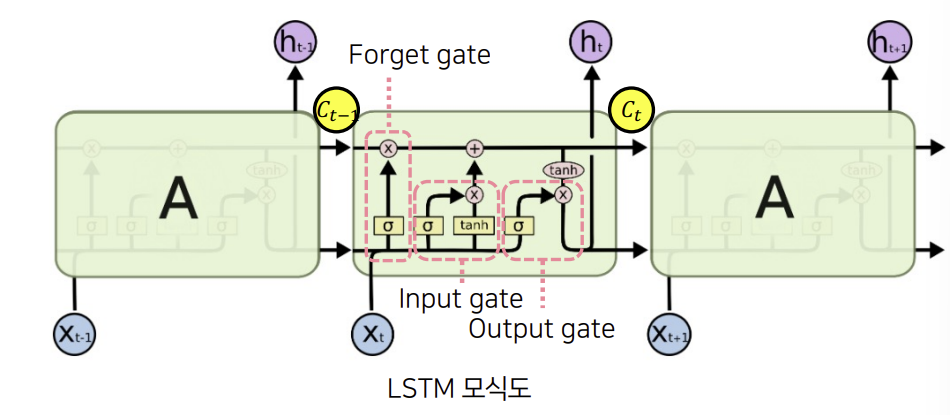
LSTM의 구조
- 3개의 변수
1. Cell state: i 시간까지 기억하고 있는 기억 메모리 2. Hidden state: i 시간에서의 모델 출력 값 3. input: i 시간에서의 입력 값
- 3개의 Gate
1. Forget gate 2. Input gate 3. Output gate
- Pytorch를 이용하여 구현
import torch
Class LSTM(torch.nn.Module): # 모델 정의
def __init__(self, ...):
super(LSTM, self).__init__()
self.lstm = torch.nn. LSTM(···) # LSTM 레이어 추가
self.fc = torch.nn.Linear(···) # 출력 MLP 레이어 추가
def forward(self, X): # 모델 forward pass
y, (hidden_states, cell_states) = self.lstm(X)
y = self.fc(y[:,-1])
return y
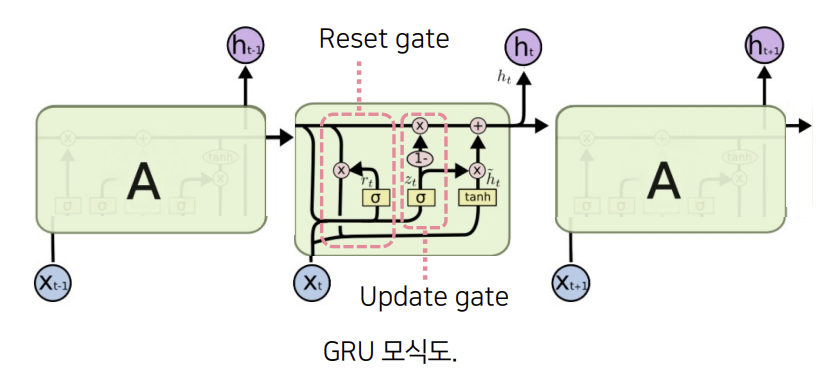
GRU(Gated recurrent unit)
- LSTM과 더불어 대표적인 RNN 기반 신경망 모델 - LSTM과 동등한 성능을 보이지만, 모델의 weight 수가 더 적어 효율적 - LSTM의 Gate를 2개로 줄임. 1. Reset gate 2. Update gate
LSTM과 GRU 성능 비교
- GRU가 LSTM보다 메모리에서 효율적이다.
=> GRU가 같은 parameter 수로 hidden state의 차원을 더 크게 설정할 수 있다.
- 비슷한 parameter 수로 설정한 GRU와 LSTM의 성능은 학습 데이터에 따라 상이하다.
- Pytorch를 활용하여 구현 가능
import torch
Class GRU(torch.nn.Module): # 모델 정의
def __init__(self, ...):
super(GRU, self).__init__()
self.gru = torch.nn. GRU(···) # GRU 레이어 추가
self.fc = torch.nn.Linear(···) # 출력 MLP 레이어 추가
def forward(self, X): # 모델 forward pass
y, (hidden_states, cell_states) = self.gru(X)
y = self.fc(y[:,-1])
return y